使用python修改PPT文本框的name
前言
临时接到了一个需求,需要使用 PPT 做一个展示界面,PPT 画完了,通过 VBA 脚本请求 RESTful 接口来控制画面中文本框的数值和颜色变化,这就需要将 PPT 中文本框原始的 文本框 xx 修改为有意义的值,方便在循环中使用 VBA 去设置值和更改颜色。

寻找需要修改的节点
使用的 PPT 版本是 2016 版本,PPT 文件是一个压缩包的形式(PPT 2007 以下是二进制格式,不能直接打开),可以解压缩查看里面的 xml 文件内容。
首先先将 PPT 文件解压,然后找到 xxx.pptm\ppt\slides\路径中的 slide1.xml 文件,文件中的内容就是第一张 PPT 的内容,使用合适的文本查看器打开并且格式化为易于查看的格式,搜索 文本框 xx,找到文本框节点,如图所示:
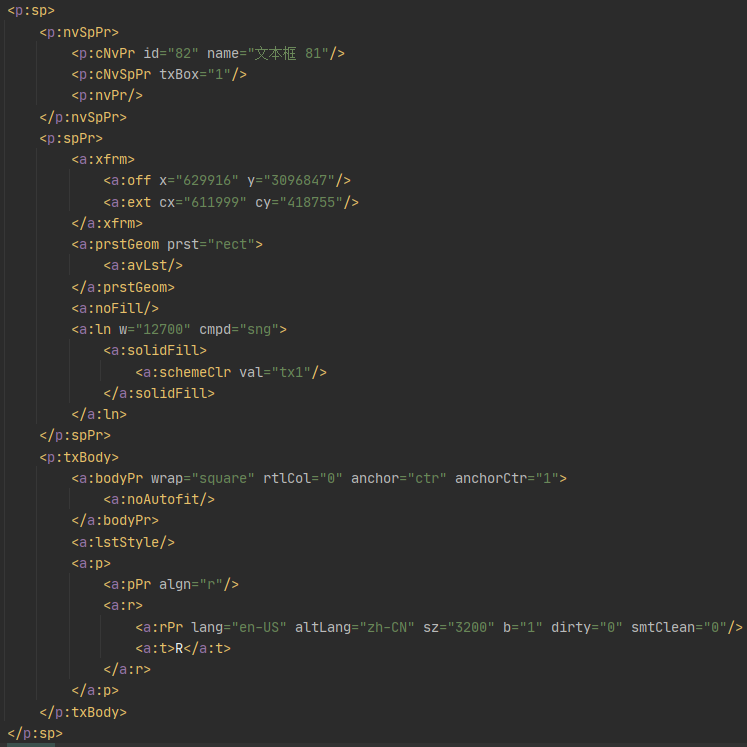
可以看到文本框节点由 <p:sp> 节点包裹,里面由三个子节点 <p:nvSpPr>、<p:spPr>、<p:txBody>组成。
<p:nvSpPr>节点中存储的内容为文本框 ID 和 name,我们需要修改的内容就在这里<p:spPr>节点中存储的内容为文本框的坐标信息<p:txBody>节点中存储的内容为文本框中的文字,可能还有其他的字体和颜色信息,由于我的是默认设置,就不深究了
修改节点信息
找到了需要修改的节点后,需要写一个程序来解析并且遍历 xml 节点,判断是否需要修改,之后进行对应的修改。解析 xml 文件可以使用 lxml 这个库,修改节点信息也可以使用它。
不过由于是 PPT 文件,应该已经有了现成的读写库,为了避免重复造轮子,搜索了一下,找到了 python-pptx 这个库。
python-pptx库
安装应该就不用说了,使用命令 pip install python-pptx 安装就可以了,会自动安装好 lxml、Pillow、XlsxWriter 这三个依赖库。
快速浏览了一下文档,没有找到符合我们需求(修改文本框节点名字)的函数或者属性,只找到了输出所有文本框中所有文字的例子:
1 | from pptx import Presentation |
运行它,输出了当前 PPT 中所有的文本框中的所有文字,如图:
寻找name属性
既然没有详细文档,那么就去翻源码好了,源码中肯定有根据节点定义好的各种属性可以直接调用。
根据刚才找到的线索节点 <p:nvSpPr> 下的 <p:cNvPr> 去源码中搜索全部文件,如图:
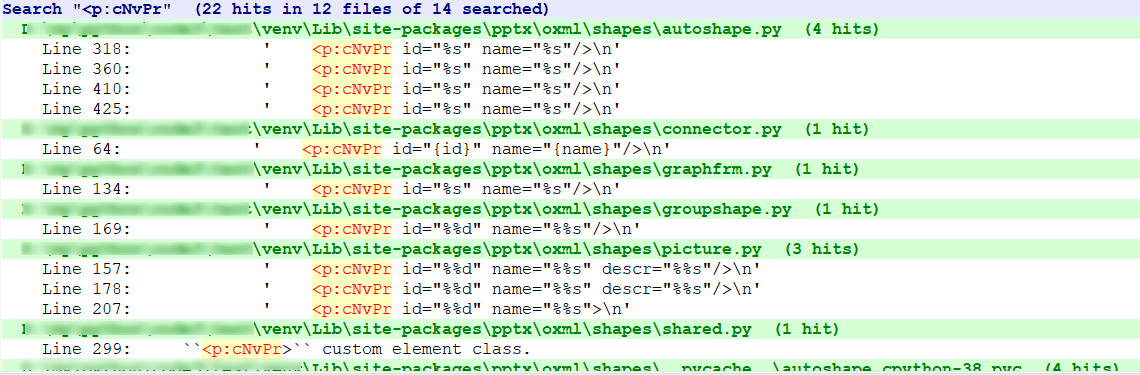
在 12 个文件中搜索到了 14处,挨个看看。经过漫长的寻找,最后找到了一个关键点,如图:

熟悉的 cNvPr,熟悉的 name 属性,不出意外就是它了。
找到它的类 BaseShapeElement,发现它是好多类的父类,也就是说这是一个基础属性,基本上每个节点都会有的。
下断点,运行上面的代码,查找 name 属性,可以看到找到了我们需要修改的 name 属性,在 shape 对象中,如图:

修改name属性
1 | from pptx import Presentation |
找到了 name 属性在哪里就好办多了, 添加一行代码,将 name 属性修改为我们所需要的名字即可(根据需求进行判断修改,此处仅为测试),不要忘了保存。
修改前:
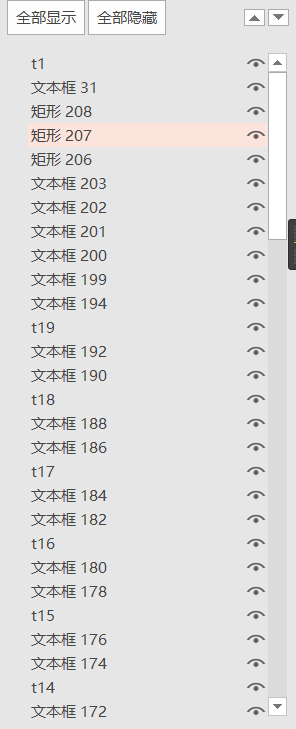
修改后:
总结
python-pptx 库还是比较好用的,可以使用它来批量生成工作中的 PPT 文档,可以批量修改文本框的 name 或者修改一些其他形状的颜色位置大小等等信息,在批量操作 PPT 文档时相当有效!
参考链接
https://python-pptx.readthedocs.io/en/latest/index.html
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
