使用AI大模型实现可以提取任意信息的通用爬虫
大家好,今天来分享一个 AI 大模型在爬虫中的“特殊”用法。
通用爬虫
在 AI 出来之前,大家可能用过下面的数据提取框架,它们可以使用算法自动分析网页结构,然后提取出网页的标题,正文,发布时间,作者等信息。当然由于算法准确度的原因,成功率不是 100%,不过在特定领域已经能达到几乎 100% 正确提取了。
现在 AI 大模型出现了,先不说反爬,内容解析的工作是不是可以让 AI 来做呢?答案是可以的。
注:以下仅讨论将数据提取操作使用大模型来做,暂不讨论数据爬取操作。
xpath 提取数据
举个例子,就拿之前的爬虫练习平台来说,是通过 xpath 的方式来提取数据的,但是每个网页的结构都不一样,所需的 xpath 也是不一样的。后面如果网页改动了结构,那之前的 xpath 就失效了,也就需要一直维护 xpath 表达式。
AI 提取数据
如果使用 AI 来提取数据呢,理论上来说肯定是可以的,而且 AI 的容错率相当高,基本上不需要改动提示词,只要一次设置好后续可以一直使用。
先来看一下效果,我将网页的所有可复制的文字内容复制出来的给到 AI,并且让它返回一个 JSON 给我:
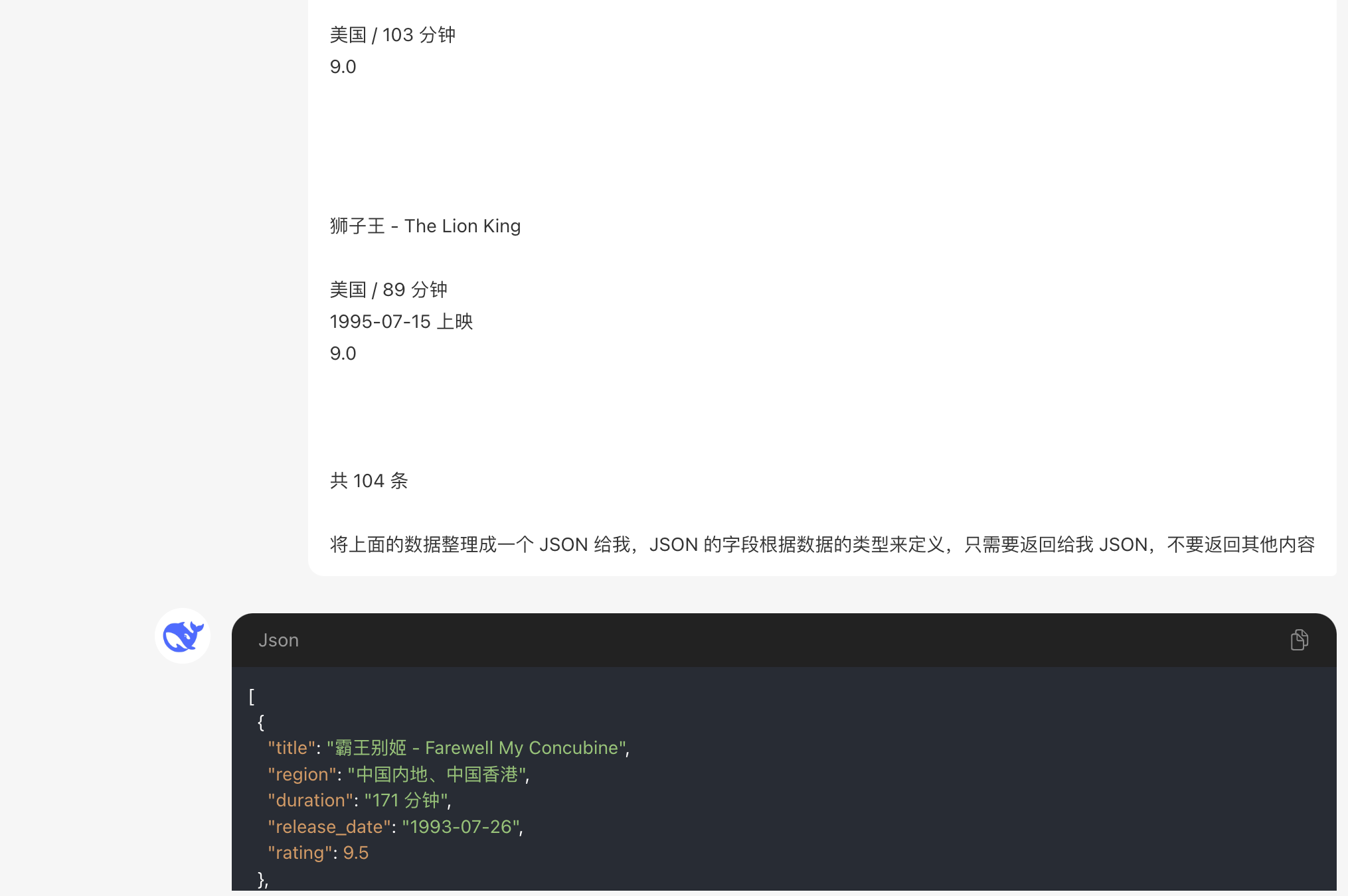
AI 处理后的数据:
1 | [ |
可以看到 AI 整理数据还是很快的,并且数据准确性还很高,甚至都不需要定义需要哪些字段,AI 会自动根据内容来推算字段。而且我使用的是 deepseek 的常规版本,并不是 R1 版本,虽然速度达不到毫秒级别,但是如果算力资源足够,那么几乎就不需要后续的维护了,而且可以做到通用,兼容各种数据。
以上是我通过手动测试的结果,实际爬取数据时,如果将整个网页 html 全都丢给 AI 的话,这样是相当浪费 token 的,因为 html 源代码中包含了JS 脚本,css 选择器等等很多我们不需要的数据,AI 都要进行处理。虽然 AI 的 token 现在已经相当便宜了,但是 JS 代码可能长度会远远超过正文内容,最终的处理费用还是相当昂贵的。
html 处理
所以在交给 AI 处理之前,还需要先将 html 源代码处理一下才行,我这里简单粗暴的提取所有的文本内容作为示例,严禁在生产环境使用,后果自负哈。
1 | import requests |

提取结果如图所示,内容还是比较少的,将其发给 AI 处理一下。
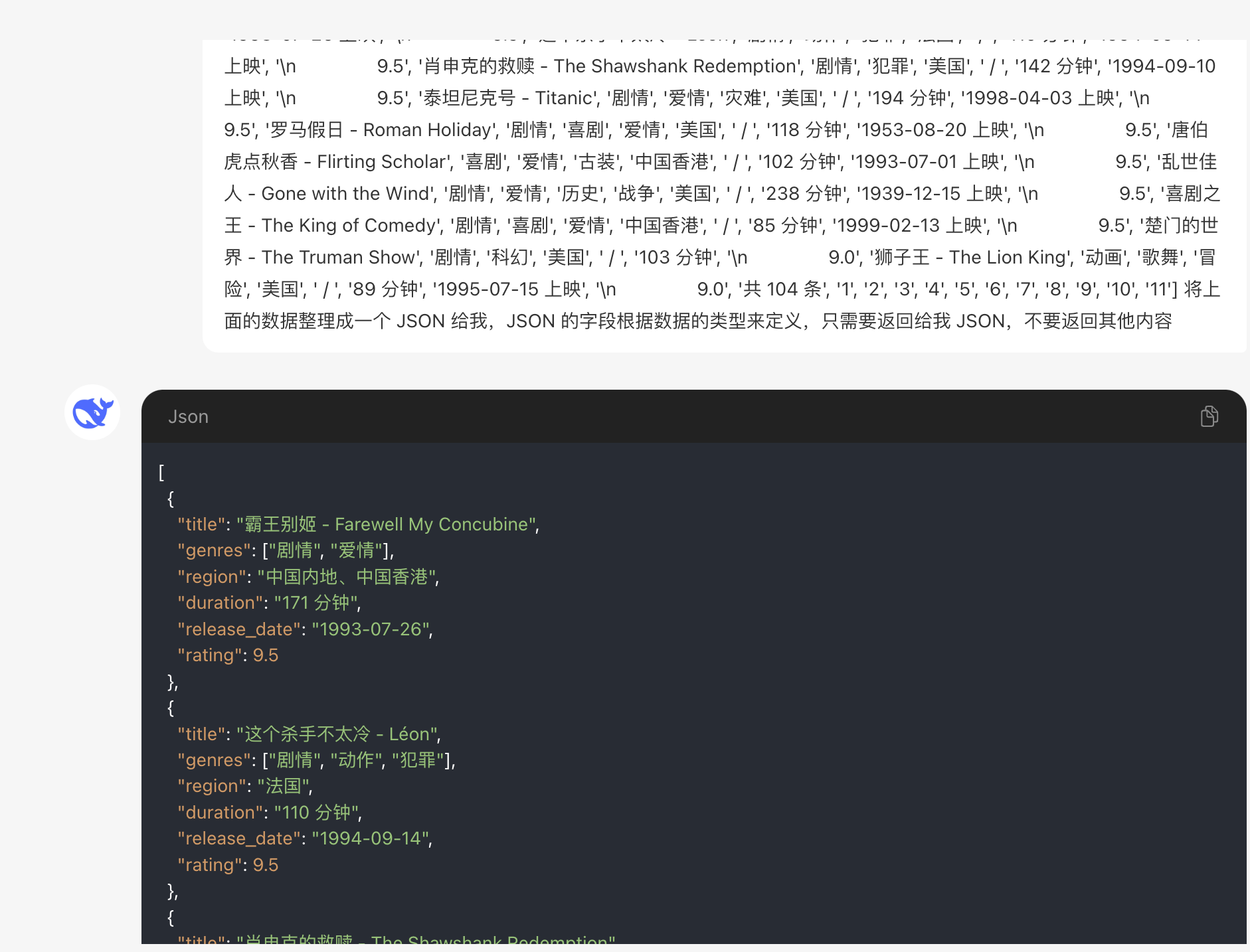
可以看到,AI 也可以正常处理以上数据,并且直接整理成 JSON 格式。
多模态大模型
上面所说的都是可以获取到网页源代码的情况,如果是 APP 端或者小程序端或者其他的数据来源呢?其实这种情况现在也已经有了解决方案,因为现在很多大模型都是多模态大模型,多模态的意思就是它不仅可以处理文本输入,也可以处理其他形式的输入,例如图像等。
只要将界面截图喂给 AI,它就会将上面的数据提取出来,并且整理成结构化数据返回,来看 deepseek 解析后的结果:
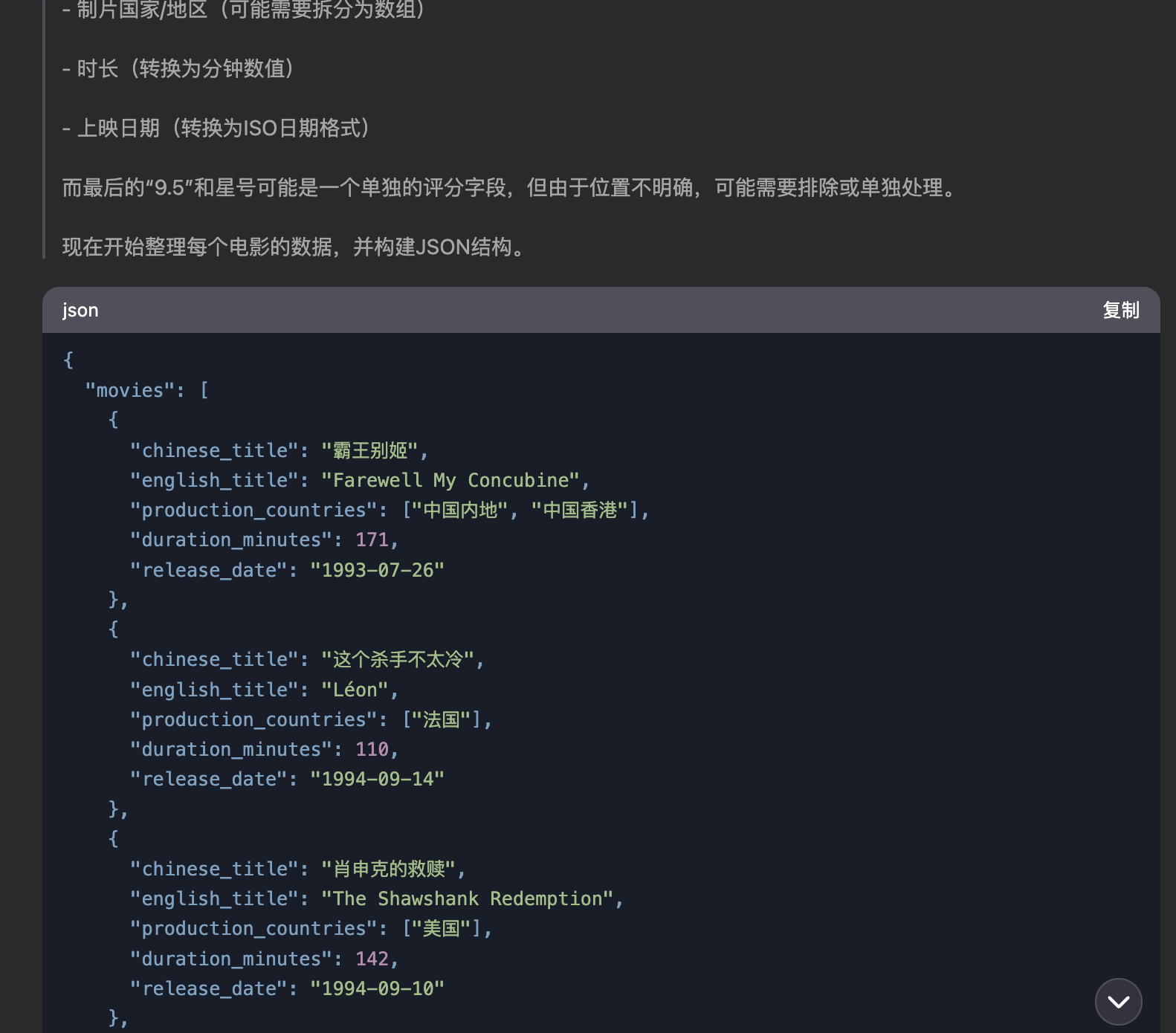
数据获取
那如何获取图片数据呢?网页可以使用自动化工具截图,APP 可以使用 adb 截图,小程序也可以使用 adb 等工具截图,不过处理这些图片数据的成本在目前看来可能还是会比较高,等后续 AI 的部署和运行成本真的降下去以后,以上方案可以极大的降低爬虫的工作量。
总结
现在 AI 已经非常成熟了,并且各种版本的本地部署成本正在降低,可以预见的是,未来大模型会越来越强,经过算法优化后所需要的配置会越来越低。数据解析和数据处理的过程都可以交给大模型来做,唯一需要考虑的就是如何获取到数据,如果将 AI 和自动化工具搭配到一起使用的话,那几乎可以做到全自动爬虫了,唯一需要考虑的可能就是风控,不过这是另一个话题了。只要可以获取到源代码或者图片数据,后续交给 AI 就可以了。
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
