JS逆向实战:JJEncode与JSFuck混淆编码全解析!
引言
还是原来的爬虫练习平台,本文的重点是 JS 逆向中的前端渲染剩下的部分,主要是 JS 代码的混淆分析。
spa10
spa10 地址:https://spa10.scrape.center/
spa10 说明如下:
NBA 球星数据网站,数据纯前端渲染, Token 经过加密处理,JavaScript 经过 JJEncode 混淆,适合 JavaScript 逆向分析。
还是老样子,数据纯前端渲染,打开 main.js 看看,数据被压缩成了一行,美化一下:
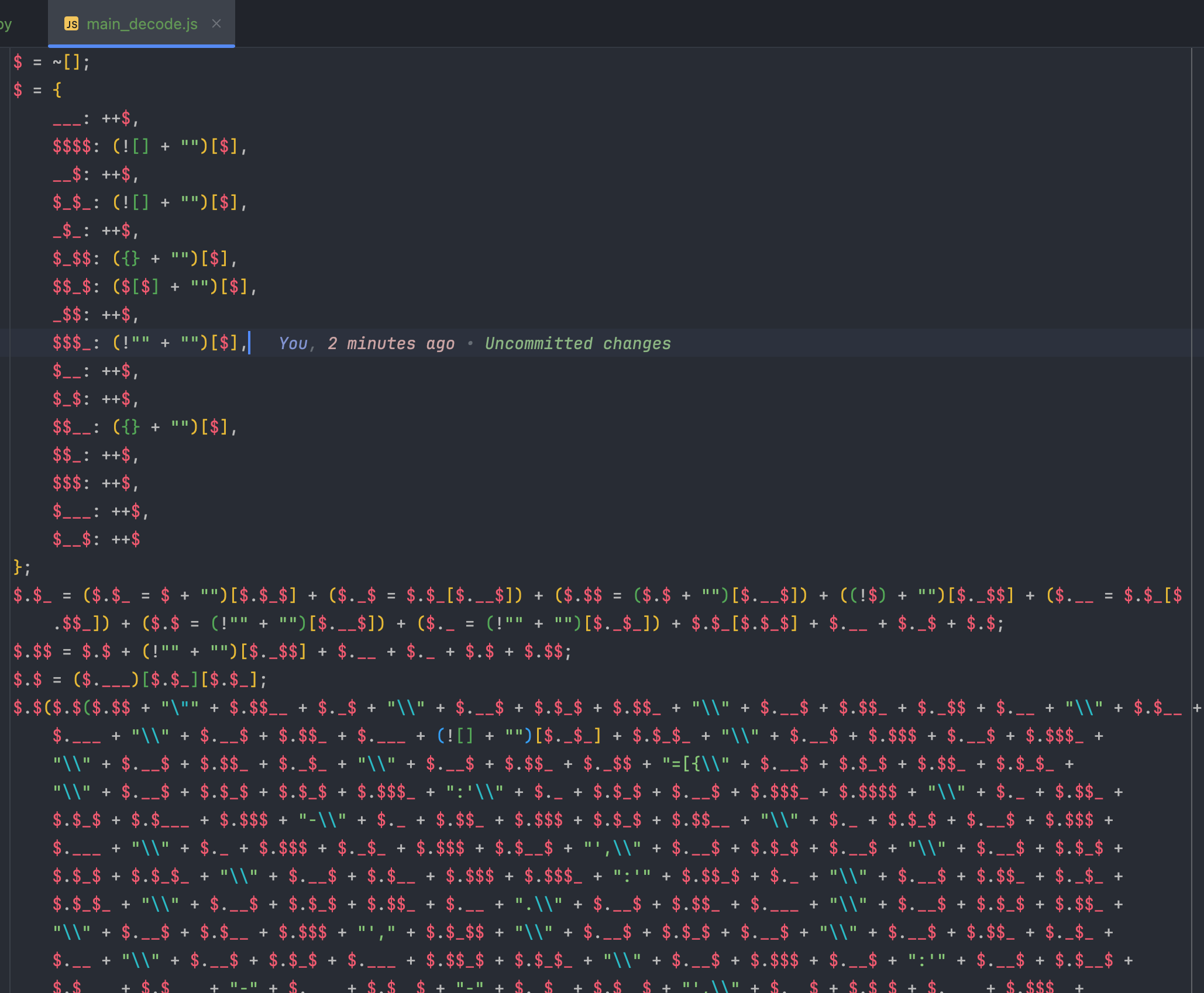
大概是这样的结构,用的是 JJEncode 编码的方式,那既然是编码,就可以解码。如何解码呢,我们要先了解编码的原理。
JJEncode 编码其实就是利用了 JS 的一些特性,例如 JS 的弱类型和隐式类型转换。
例如 (![]+"") 会得到字符串,正常来说一个空数组被取反会进行隐式类型转换而不报错,也就是说 ![] 会得到布尔值 false,然后将 false 和空字符串相加又会发生隐式类型转换,最终得到字符串 false。
还有,开头的 $=~[] 其实就是赋值语句,最终 $ 的结果是 -1,为什么呢?首先 ~ 是取反运算符,它的运算对象是整型,但是实际是空数组, 所以这里又会发生隐式类型转换,空数组会先被转换成空字符串,空字符串又会被转换成整形 0,最终对 0 进行取反,得到 -1。
了解了以上内容后,我们来运行一下代码看看前面两个赋值语句的结果:
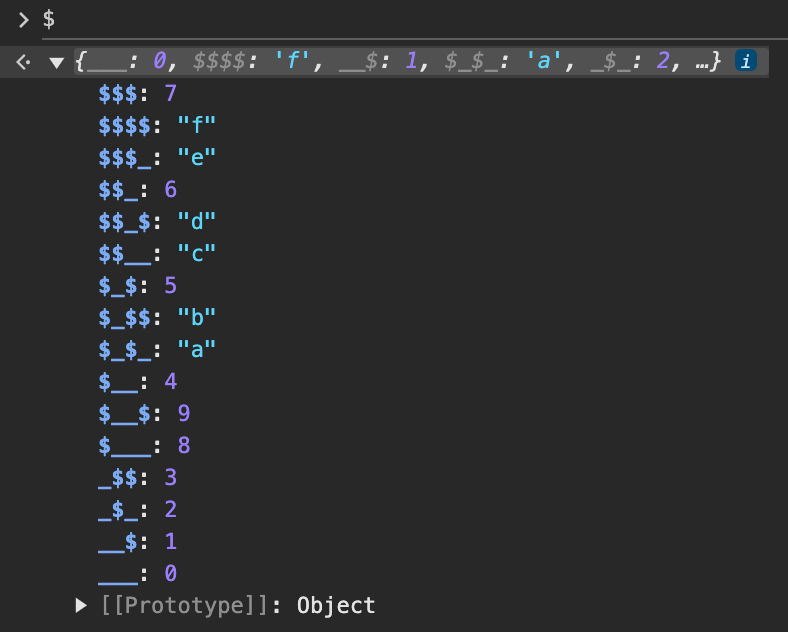
可以看到,$ 中就是一些数字和字符串。

再来看后续的代码,只需要根据需要对上面的字符串进行拼接或者相加操作,即可得到几乎任意的代码,只是难以读懂罢了。
那如何解码呢?既然代码是动态拼接的,我们静态分析就不太可能了,这个时候需要动态执行,让它自己解码,我们只需要获取它解码后的结果但是不要直接运行就可以了。
来看下代码的结构:
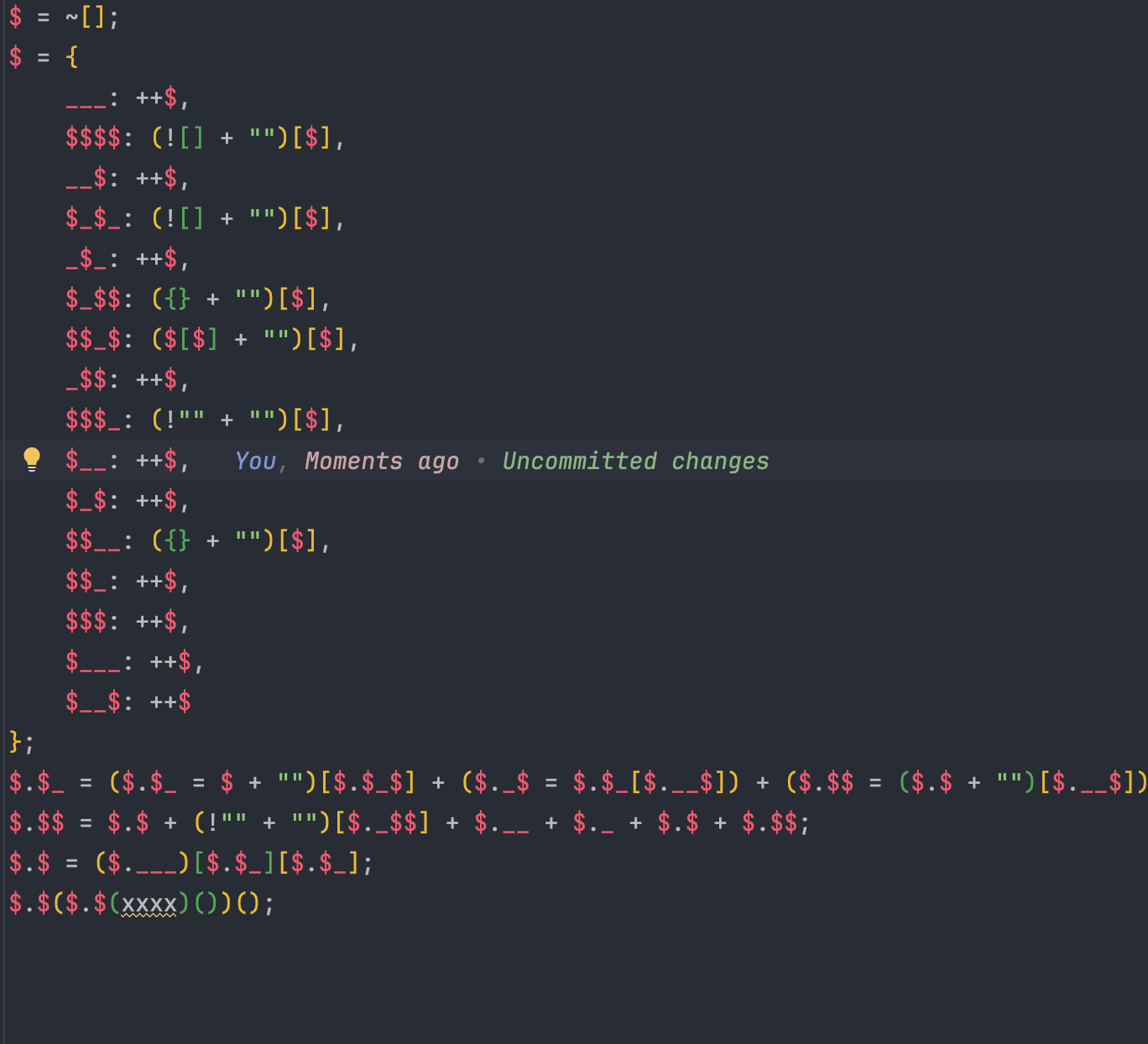
我将实际的内容换成了 xxxx,方便分析,这时候我们可以看到其实整个结构就是 JS 中的匿名函数,因为这段代码必须保证在放到浏览器中就可以正常执行,而不是让其他程序来调用,所以它这里用了匿名函数。
针对匿名函数,我们知道 JS 中有一个函数叫 toString,我们可以用它来实现将匿名函数转化成字符串来输出,而不是直接执行。
来看最终的代码:
1 | import subprocess |
为了方便输出字符串,我这里对字符串增加了一个 print 函数,方便链式调用。首先定义了 print 函数,然后对原有的 JS 代码去掉空白和回车后,去掉最后的三个字符(去掉三个字符主要是去掉自执行的两个括号和一个分号,这样的话执行的就是函数本身,但是没有调用函数),然后拼接 toString 方法转成字符串,然后调用 print 方法输出最终要执行的函数的代码。
来看下运行结果:
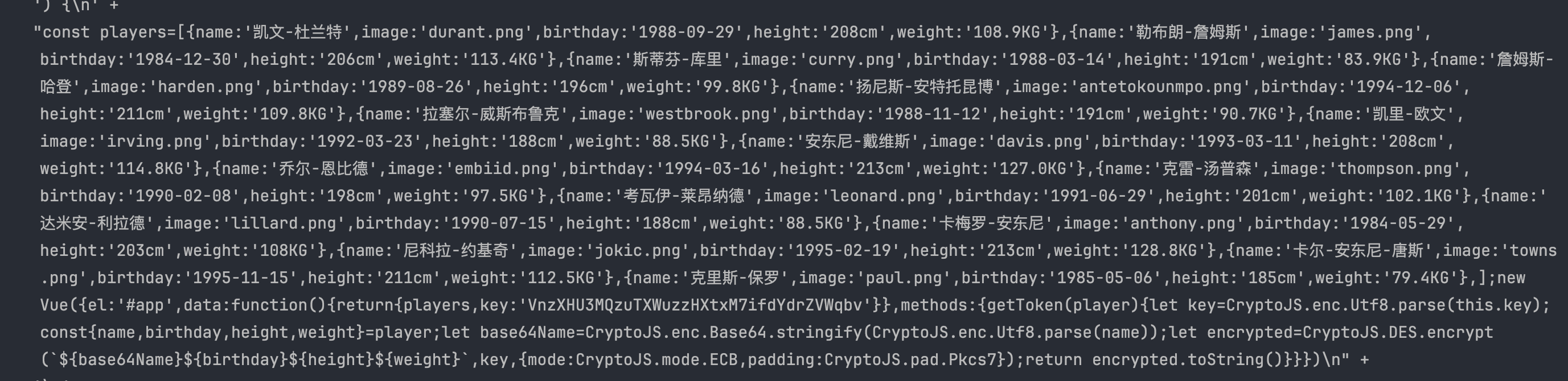
数据已经都提取到了,剩下的就和前面的流程一样了,我这里就不重复写了。
最终代码见:https://github.com/libra146/learnscrapy/tree/main/js/spa10
spa11
spa11 地址:https://spa11.scrape.center/
spa11 说明:
NBA 球星数据网站,数据纯前端渲染,Token 经过加密处理, JavaScript 经过 AAEncode 混淆,适合 JavaScript 逆向分析。
根据前面的分析,我们拿到代码直接看代码结尾:
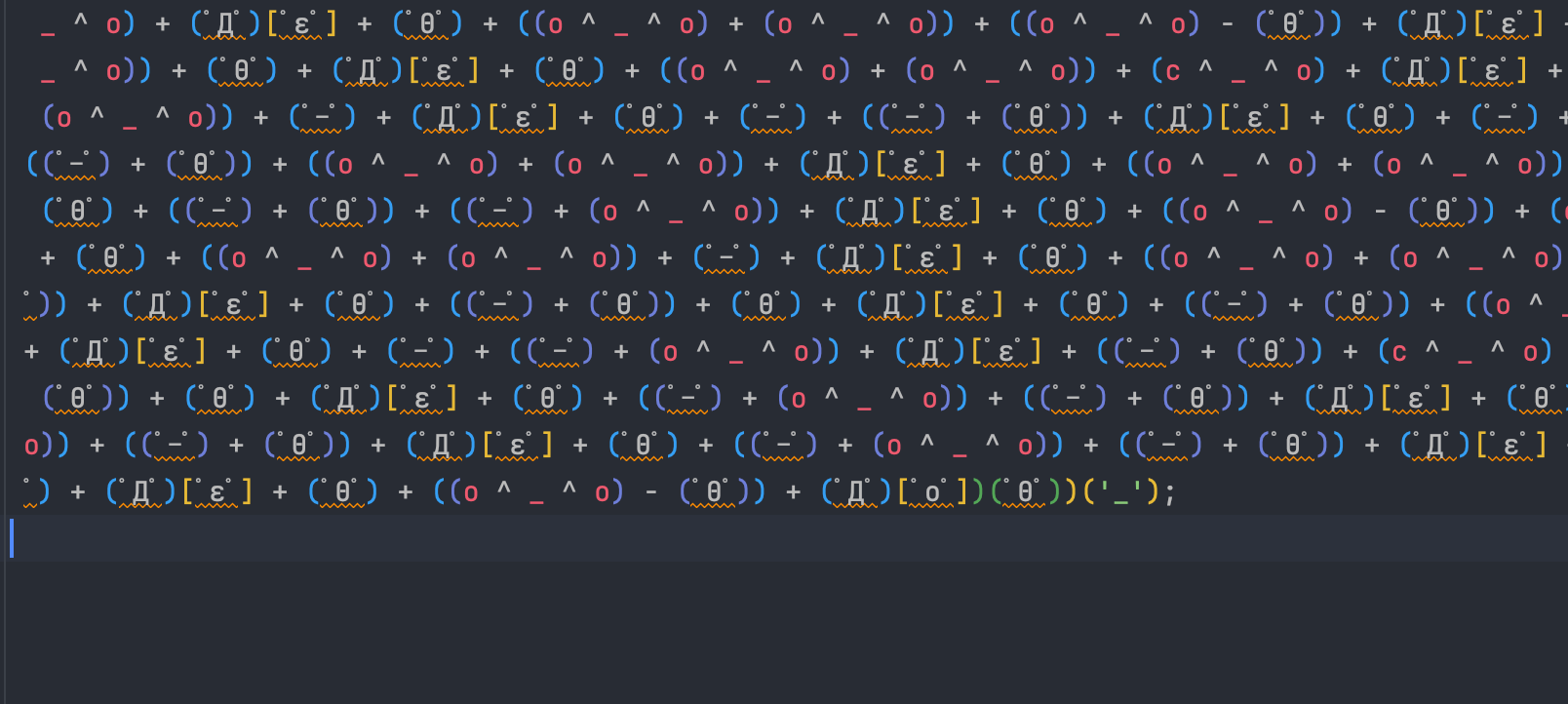
无非就是把刚才的 $ 字符换成了颜文字,其实道理还是一样的,仔细观察最后几个字符,其实只是把刚才的匿名函数的无参数调用换成了有一个参数的调用。
我们直接套用 spa10 的代码即可。
1 | import subprocess |
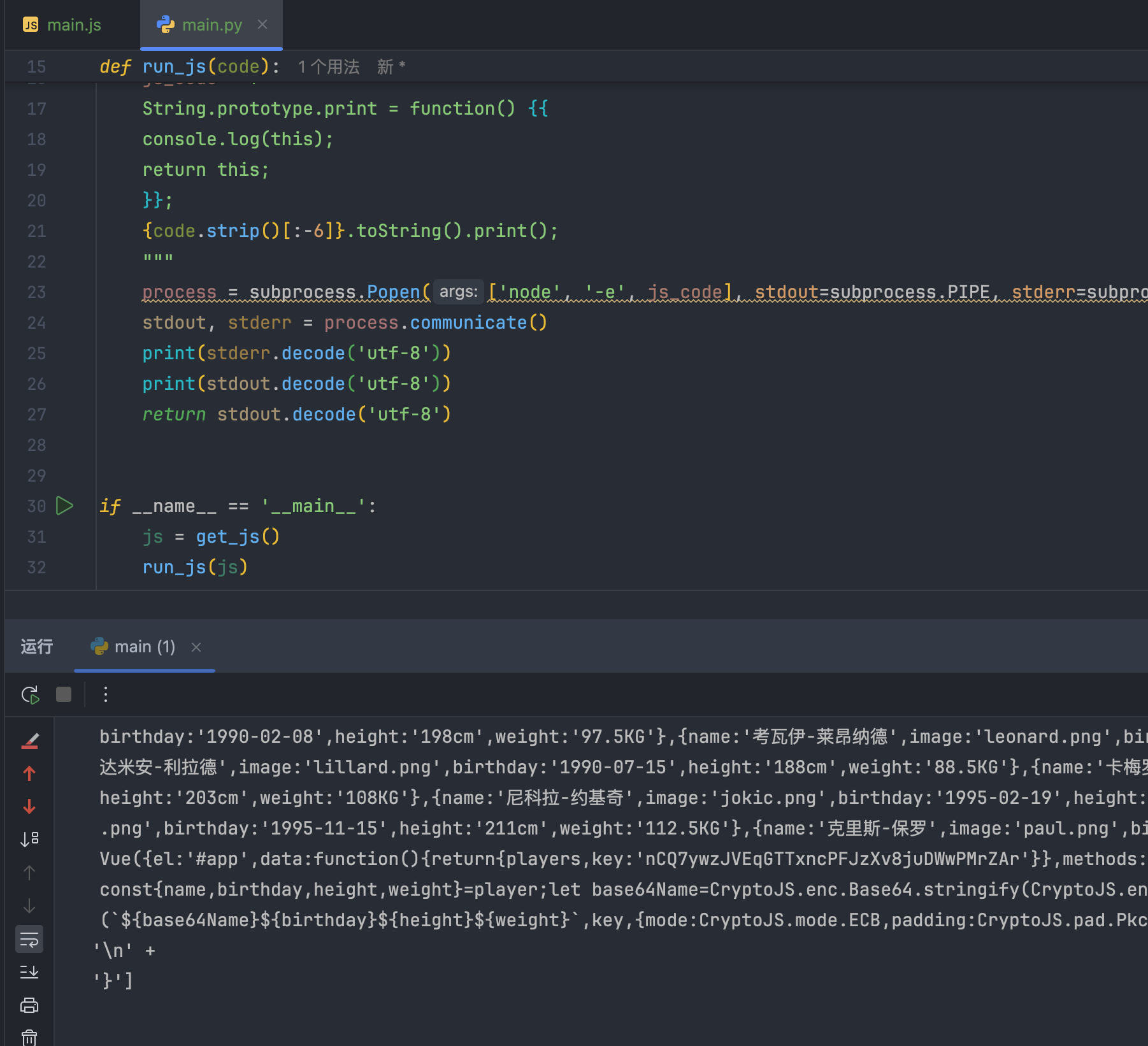
查看结果,符合预期,最终代码见:https://github.com/libra146/learnscrapy/tree/main/js/spa11
spa12
spa12 地址:https://spa12.scrape.center/
spa12 说明:
NBA 球星数据网站,数据纯前端渲染,Token 经过加密处理, JavaScript 经过 JSFuck 混淆, 适合 JavaScript 逆向分析。
先看下 JSFuck 混淆的代码长啥样:
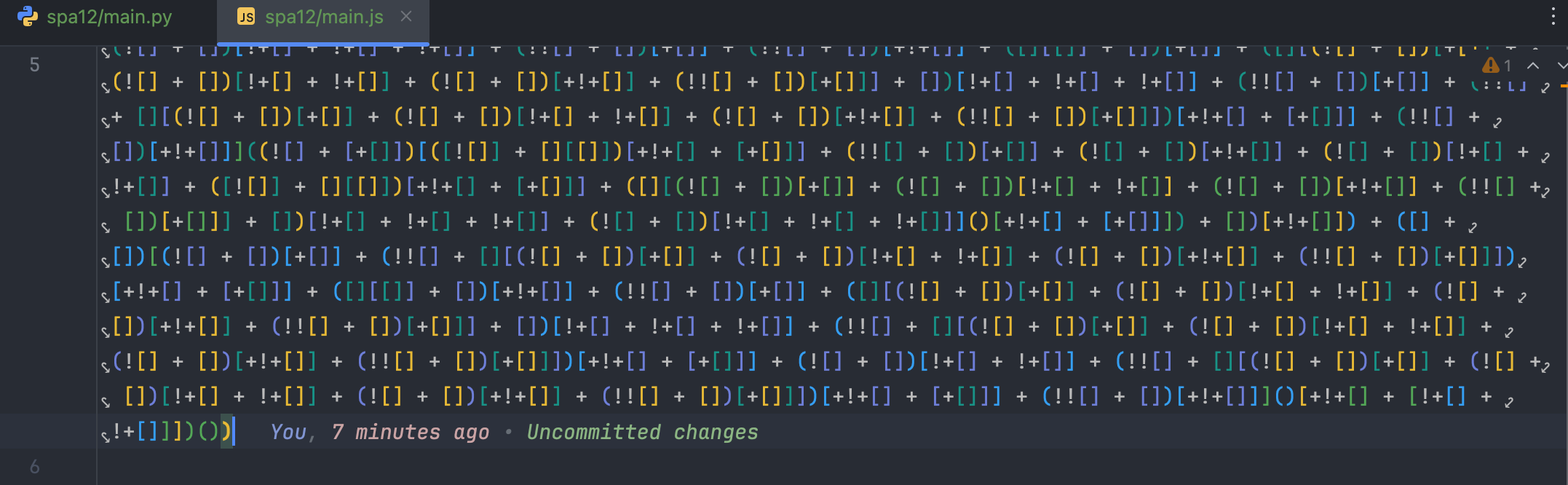
还是老样子,这次无非就是括号在里面了,不知道后面的那个括号是干嘛用的,先用老方法试一下:
1 | import subprocess |
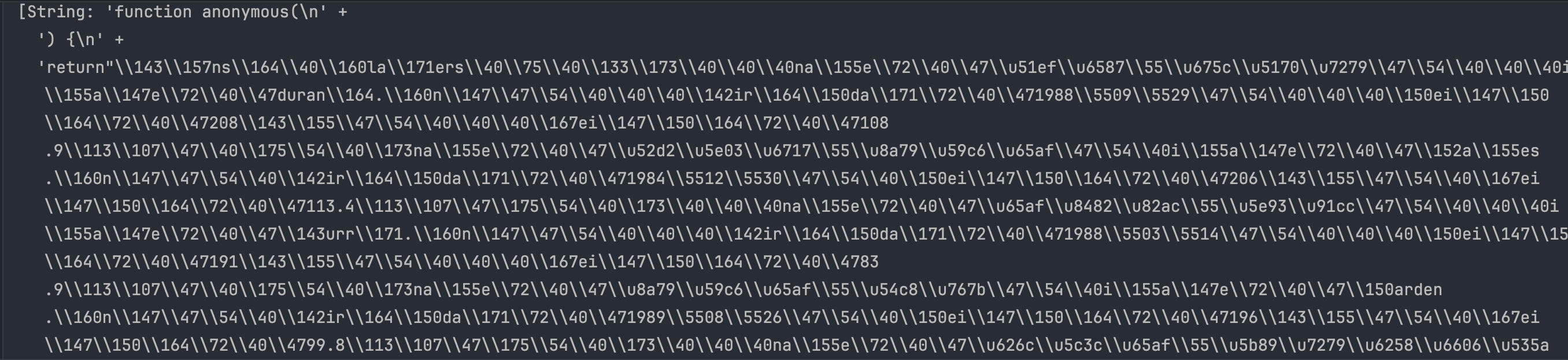
看起来是返回了一个匿名函数,函数的内容编码过了,无法直观地看出来内容,并且返回的是一个字符串,貌似不是可执行的内容,我们来分析一下代码结构。
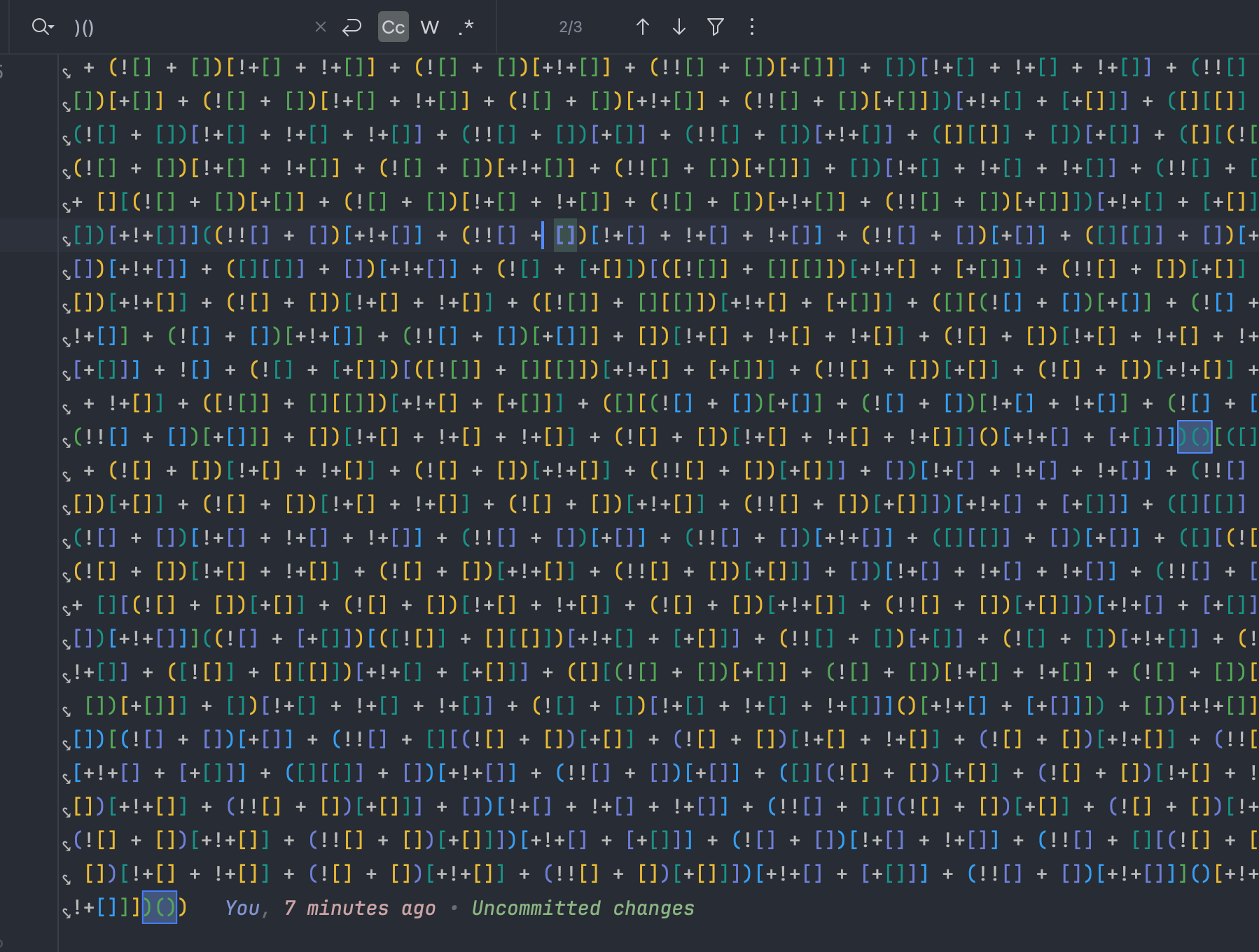
搜索一下匿名函数的特征,搜索到三个,我们把这三个匿名函数都打印出来看看:
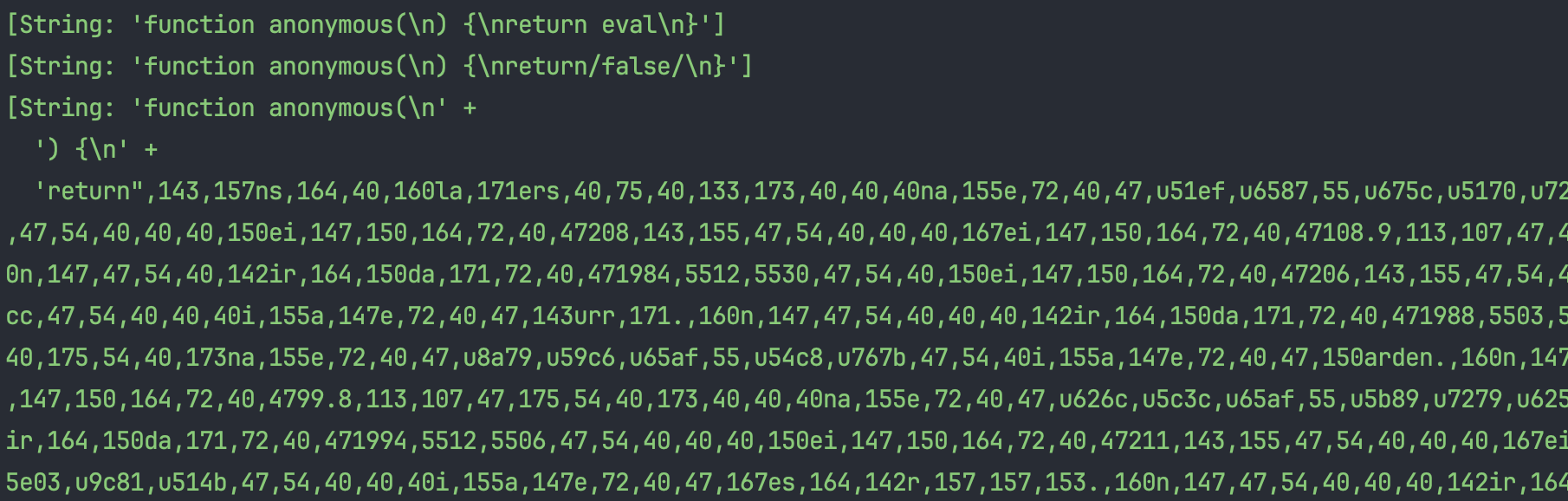
可以看到,其中使用了 eval 函数,那说明刚才的那个 return 返回的字符串,有可能是把原来的代码编码成了参数传给了 eval,那我们改变思路,让刚才的函数正常执行,因为这种编码过的代码其实在 JS 中让它正常执行传给一个变量就可以自动还原成正常可读的字符串了。
改一下代码:
1 | import subprocess |
运行结果:

拿到了结果,结束。
最终代码见:https://github.com/libra146/learnscrapy/tree/main/js/spa12
总结
这次的几个编码类型的混淆其实难度并不大,只是比较繁琐,耐心点分析下代码结构一般都可以直接秒杀。
而且这种混淆方式对代码的保护能力也比较弱,不推荐通过这种方案来混淆代码,玩玩可以,但是不推荐用哈哈。
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
