时间分布统计小技巧:任务执行耗时一目了然
引言
今天接到一个统计任务,要对一个流水表中的数据按照时间进行分级统计,分享一下实现方法。
分级统计
流水表中有一个字段是任务的执行时间,就是一个任务执行了多长时间。
举个例子:
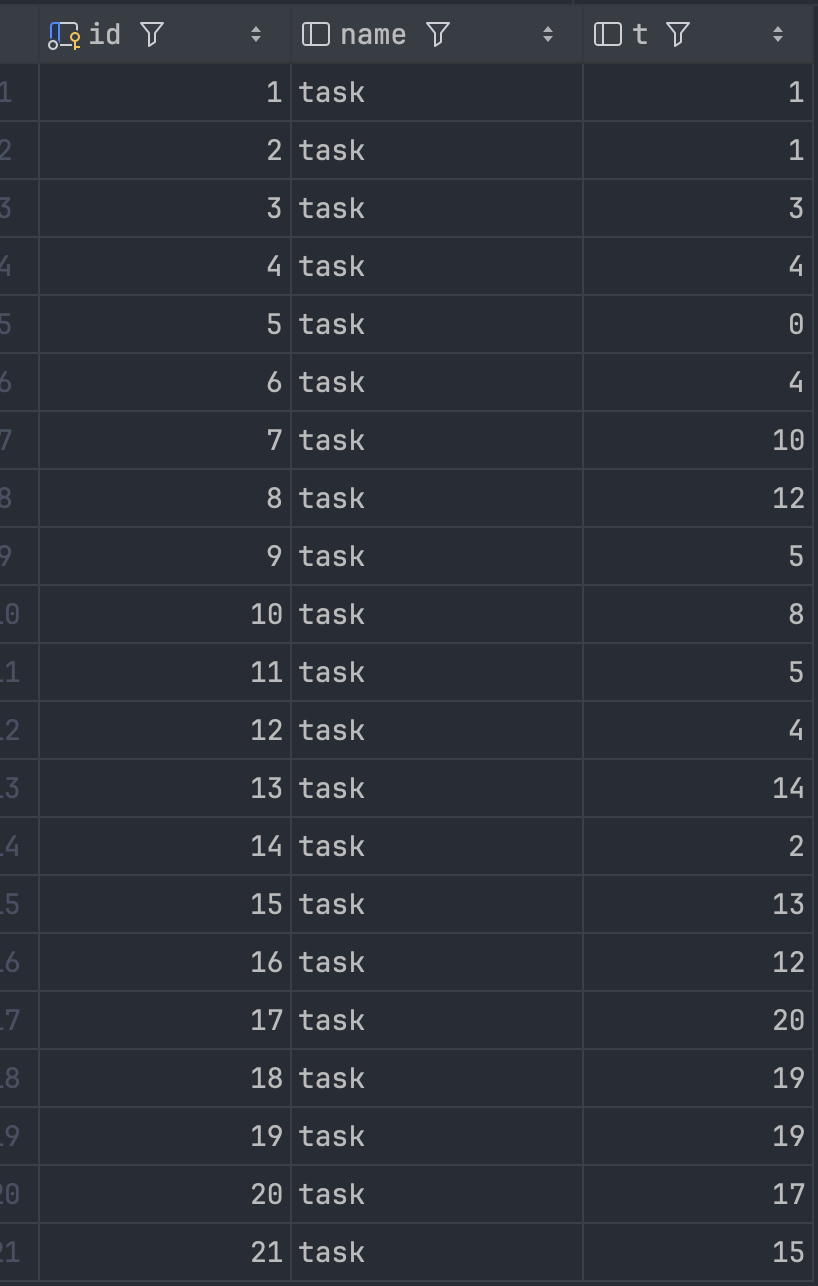
有这么一个表,想要根据时间对数据进行统计,统计结果为:任务执行耗时 0-5 秒的有多少,执行耗时 5-10 秒的有多少个,依此类推。
要如何统计呢,来看 SQL:
1 | select name, t, count(t) as cnt |
来看执行结果:
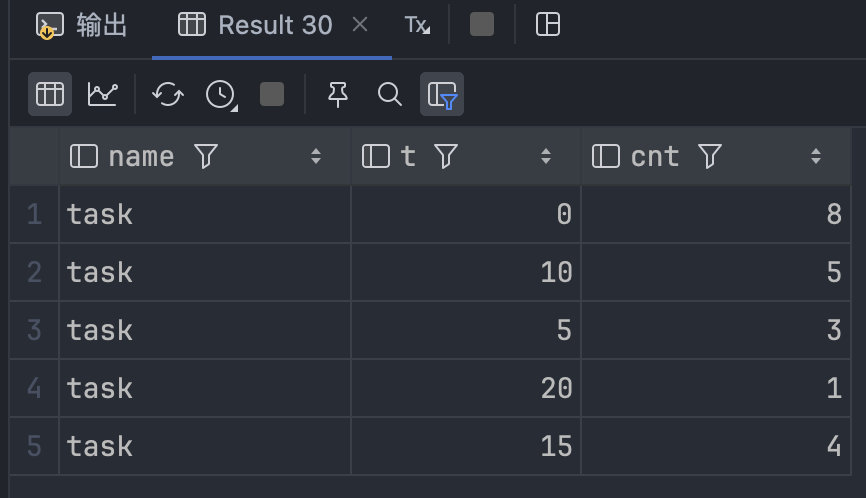
查看原始数据,人工校验一下,没有问题,统计结果是对的。
分级原理
既然已经有了答案了,那么这个 SQL 的原理是什么呢?
我们来分析一下,既然要将数据进行分级,那么我们首先要确定的就是要按照数字几的倍数来分级,这里我们选择 5,也就是说数据的范围就是 0-5,5-10,10-15 等等依此类推。
定好数据范围后,核心计算逻辑其实就是 TRUNCATE 函数,它的作用是丢掉小数位,例如我用 18 除以 5 以后,正常来说得到的是一个浮点型,例如 3.6,那这个时候我们将它去掉小数位后重新乘以 5,结果就只能是 5 的倍数了,结果是 15,这个时候我们就可以得到结果,18 是属于 15-20 这个区间的,18 这个数据就会落入 15-20 这个区间内。
其实,说白了,我们上面的操作就是强制让浮点数丢失精度,丢失的精度部分顶多就是0-1,也就是说顶多会丢掉 5,最少会丢掉 0,这个方法可以让任何一个数字变成一个比自己小的 5 的倍数的一个数字,方便外层的 SQL 进行 group by 统计。
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
