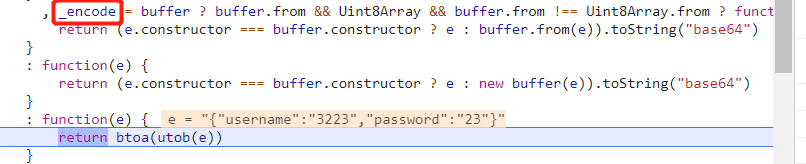
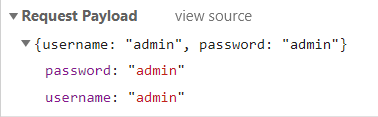
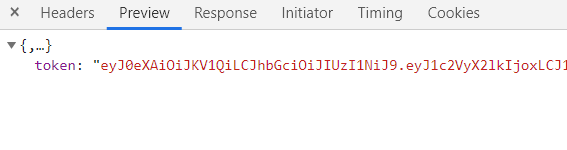
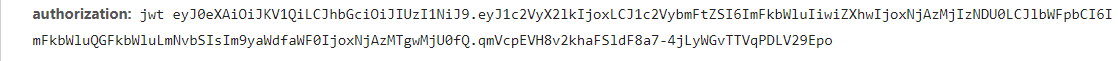classLogin3DownloaderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects.
@classmethod deffrom_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s
defprocess_request(self, request, spider): # Called for each request that goes through the downloader # middleware.
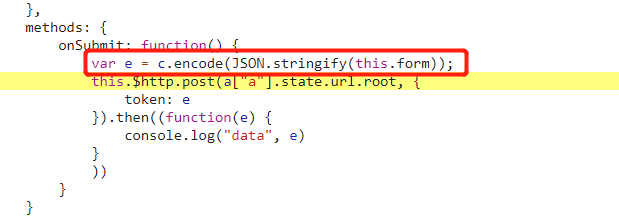
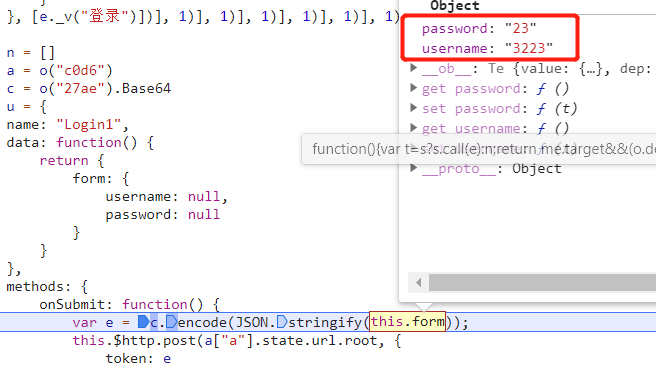
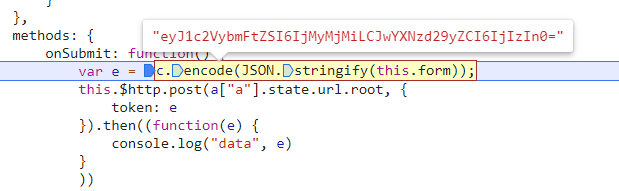
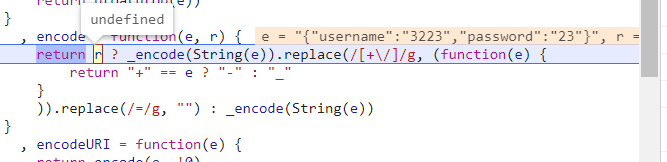
# Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called # 由于第一个登录请求是不需要jwt的,这时候实际上也没有请求到jwt,所以判断一下 if spider.jwt: request.headers.update({'authorization': f'jwt {spider.jwt}'}) returnNone
defprocess_response(self, request, response, spider): # Called with the response returned from the downloader.
# Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response
defprocess_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception.
# Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass