前言
上一篇文章中爬取了爬虫练习平台的所有 ssr 网站,都是比较简单的,没有反爬措施,这次来爬一下后面的 spa 系列。
环境准备
这里沿用了上篇文章的环境和设置,就不重新搭建环境了。
开始爬取
spa1
spa1 说明如下:
电影数据网站,无反爬,数据通过 Ajax 加载,页面动态渲染,适合 Ajax 分析和动态页面渲染爬取。
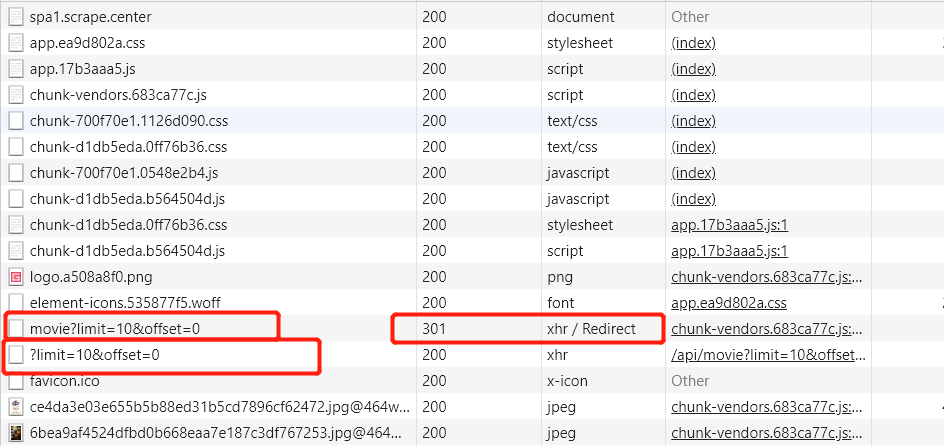
还是无反爬,Ajax 加载数据,那么最简单的方法就是打开 Chrome 控制台, 找 xhr 请求。
![]()
一共有两个请求,第一个请求经过了 301 重定向,所以实际接收到数据的是第二个请求。
![]()
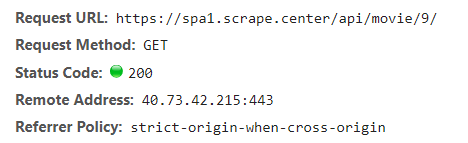
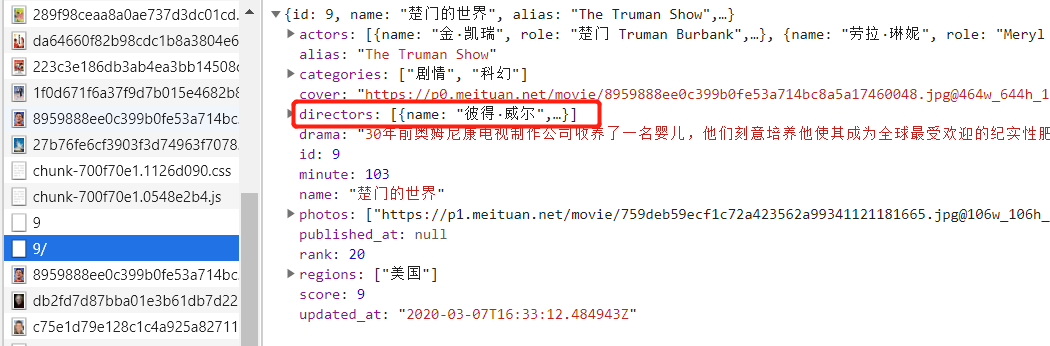
查看数据,基本数据都有了,但是没有作者信息,随便点击一个电影,查看详细信息,查找接口。
![]()
![]()
通过 id 和另一个 API 接口获取详细信息,可以找到作者,OK,开始写代码。
其他代码和之前从 HTML 中解析数据的逻辑一致,只是在解析方法上不一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class SPA1Spider(scrapy.Spider):
name = "spa1"
def start_requests(self):
urls = [
f'https://spa1.scrape.center/api/movie/?limit=10&offset={a}' for a in range(0, 100, 10)
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
result = response.json()
for a in result['results']:
item = SPA1Item()
item['title'] = a['name'] + a['alias']
item['fraction'] = a['score']
item['country'] = '、'.join(a['regions'])
item['time'] = a['minute']
item['date'] = a['published_at']
yield Request(url=response.urljoin(f'/api/movie/{a["id"]}/'), callback=self.parse_person,
meta={'item': item})
def parse_person(self, response):
result = response.json()
item = response.meta['item']
item['director'] = result['directors'][0]['name']
yield item
|
因为是通过 API 接口进行遍历的,所以使用总的页数进行循环就可以得到所有的起始 URL。
然后通过读取 JSON 格式的响应,依次循环获取数据,然后进入到详情页获取作者信息,最后返回数据。
完整代码详见https://github.com/libra146/learnscrapy/tree/spa1
spa2
spa2 说明如下:
电影数据网站,无反爬,数据通过 Ajax 加载,数据接口参数加密且有时间限制,适合动态页面渲染爬取或 JavaScript 逆向分析。
和 spa1 相比多了一个数据接口参数加密,先打开控制台看一下多了什么参数。
![]()
接口没有变,只是多了一个 token 参数,接下来来寻找一下这个 token 是怎么生成的。
既然是网络请求,而且 URL 中包含 token,那么分析 token 来源就要从 URL 断点入手。
![]()
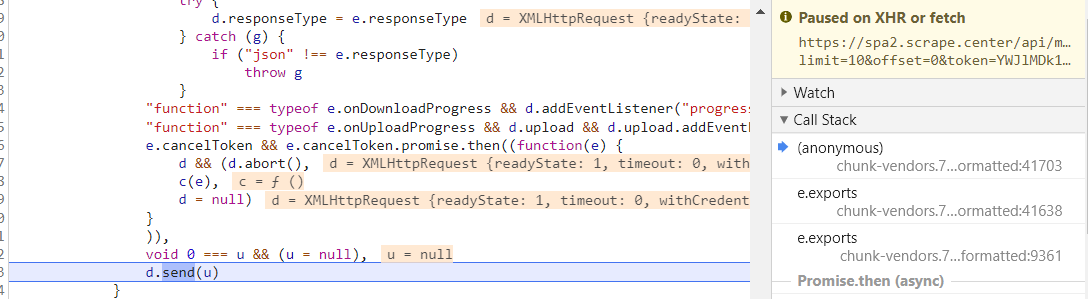
下断点,凡是包含 token 字符串的 URL 全部会断下,刷新页面,断点断下,格式化 js 代码,可以看到断下的位置为 send 函数,用来发送请求。
![]()
![image-20250112172618999]()
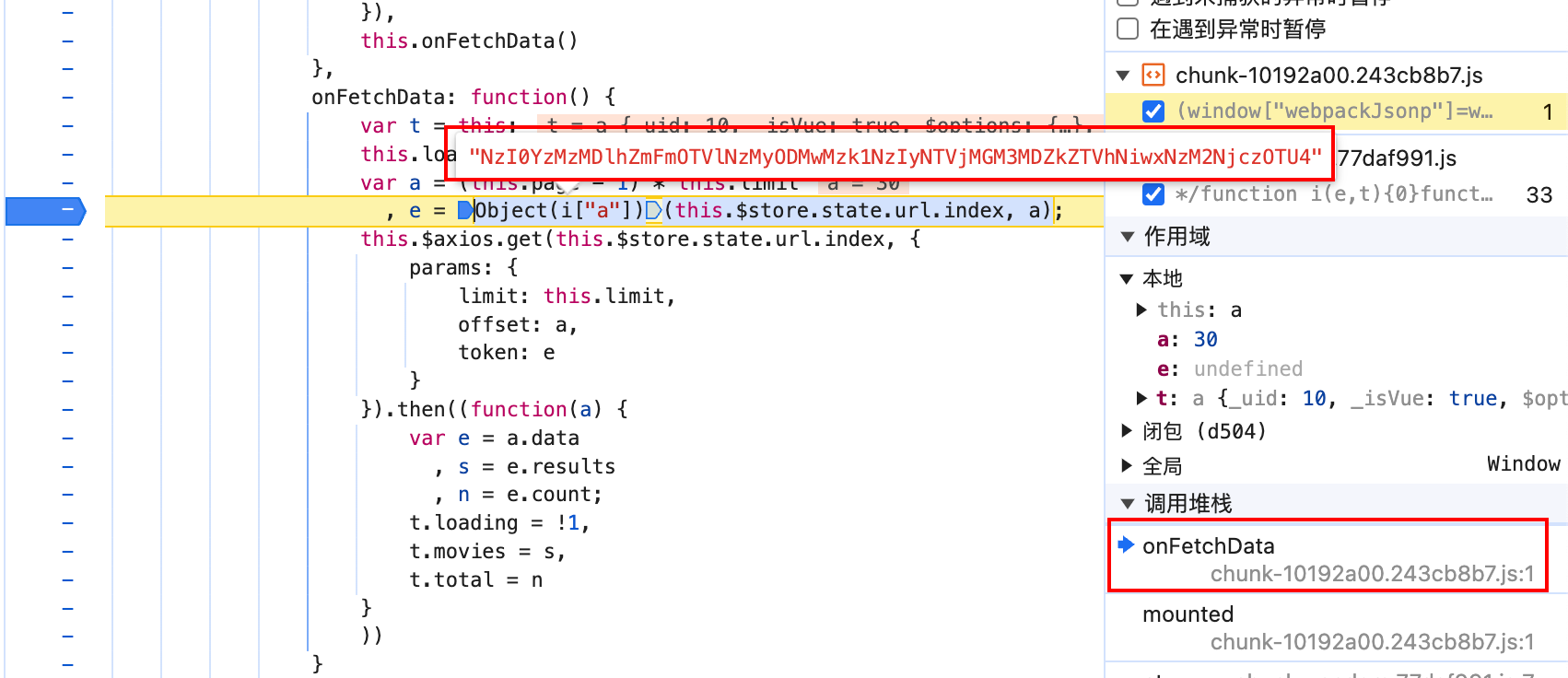
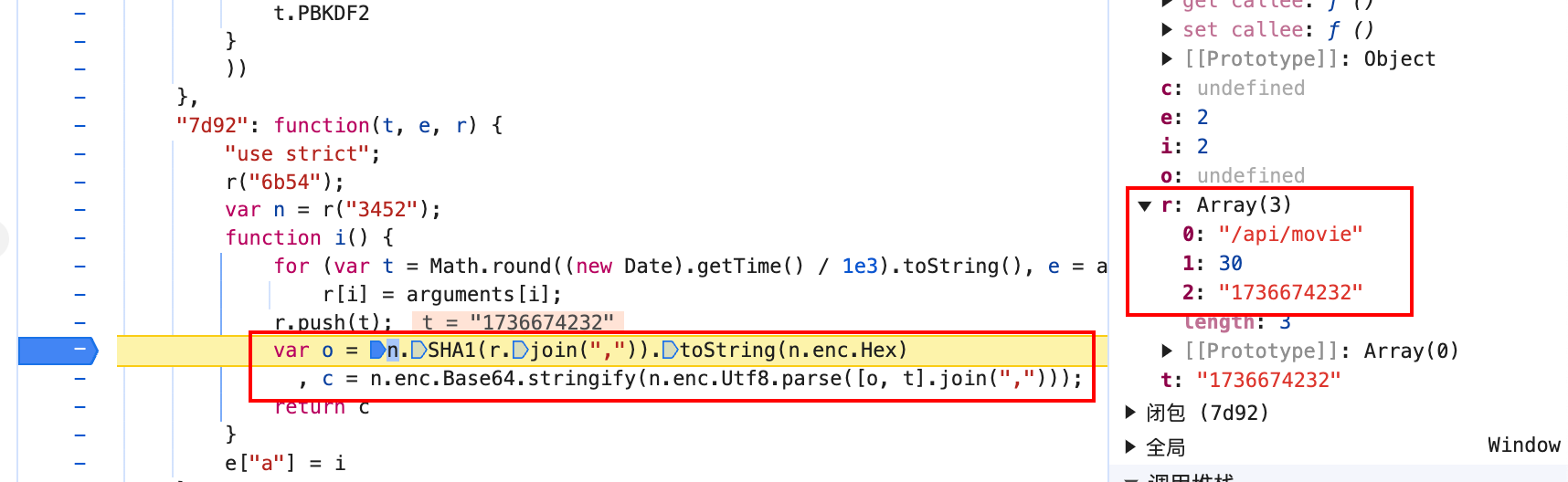
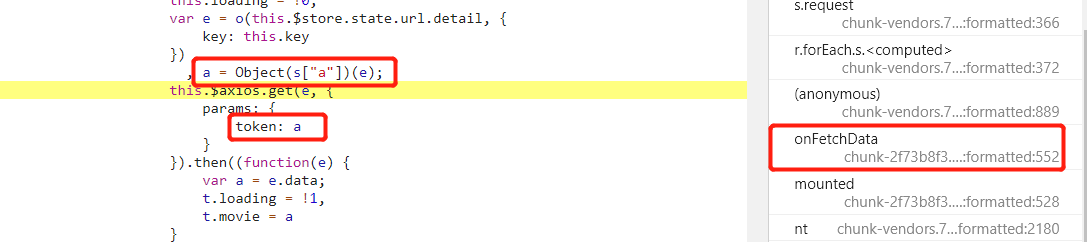
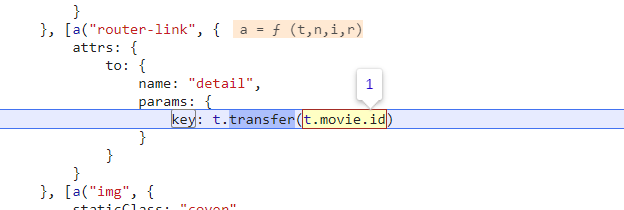
按照右侧调用栈依次往下看,发现在 onFetchData 函数附近发现了 token 参数,取消 URL 断点,在 token 的生成位置下断点。重新刷新页面,断点断下。
![image-20250112172708657]()
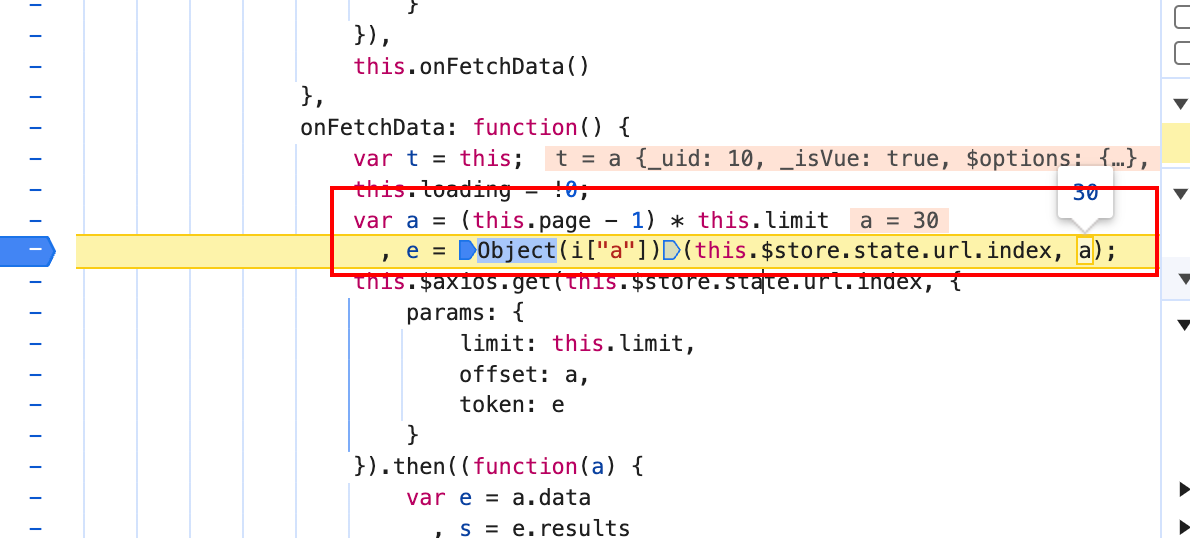
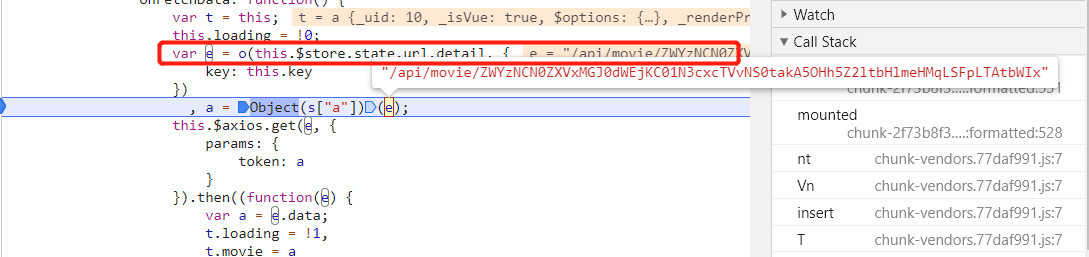
结合上面的图片,可以看到,e 变量就是 token,通过一个函数传入两个参数计算后得到了 token,需要的两个参数是当前的 URL,和一个 a 变量,a 变量是上面计算得出来的。单步进入代码查看具体执行了什么。
![]()
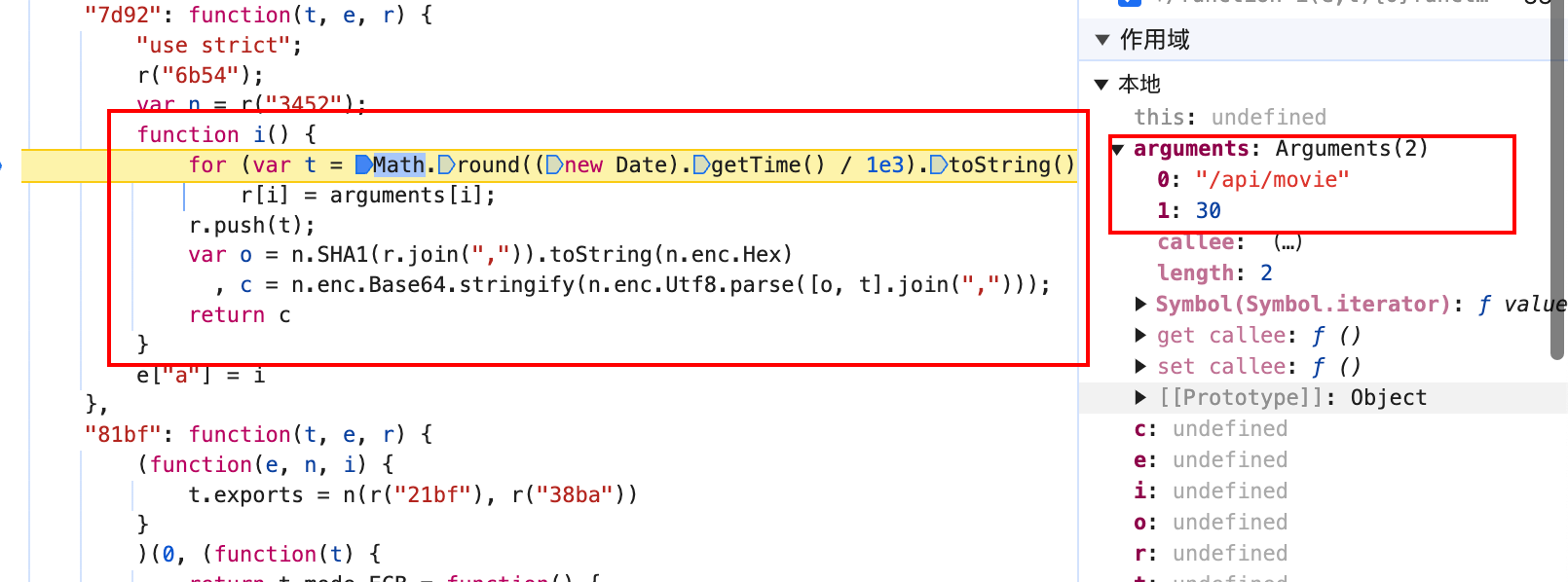
看不到具体的信息,应该是在执行 Object(i["a"]),步出,继续单步跟,进入到实际计算 token 的函数中。
![image-20250112172941765]()
进入到了新的代码块,这次可以看到 sha1 函数和 base64 函数,应该是加密函数所在位置了,从右侧也可以看到我们传进来的两个参数。
![image-20250112173108207]()
函数获取了所有的参数,并且 push 到 r 变量中,拼接成字符串,并且计算 sha1 值后,跟时间戳再次拼接,使用 base64 编码,然后返回,以上逻辑就是 token 的计算逻辑。
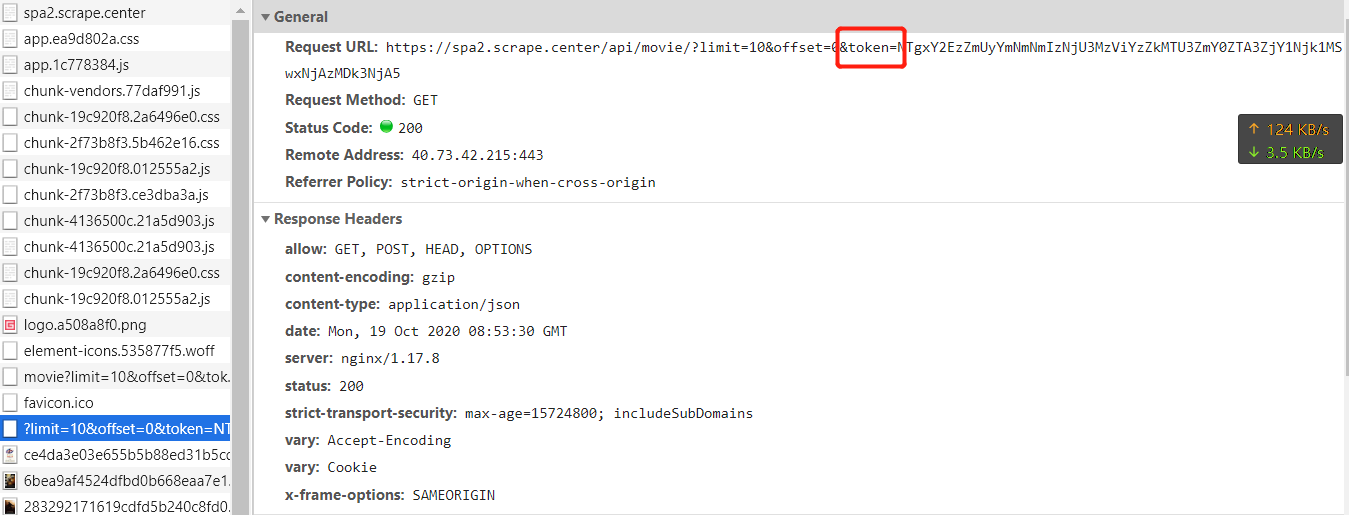
别急,还没完,获取首页信息的 token 算法已经有了,但是获取详细信息的页面 URL 是这样的:
![]()
token 应该和上一个请求是一样的,但是红框中这一段信息上个请求没有返回,那么只可能是本地生成的,我解码看了下,结果是:ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb20 一堆看起来像乱码的东西,还得分析它是怎么来的,既然都用到了 token,那么它在计算完前边这段信息之后肯定会去计算 token 的,所以继续下 token 断点然后往前找就可以了,话不多说继续下断点。
![]()
![]()
仍然是断在了 send 函数上,继续寻找熟悉的 onFetchData 函数,熟悉的 token,取消 URL 断点,在 token 生成这一行下断点,刷新页面。
![]()
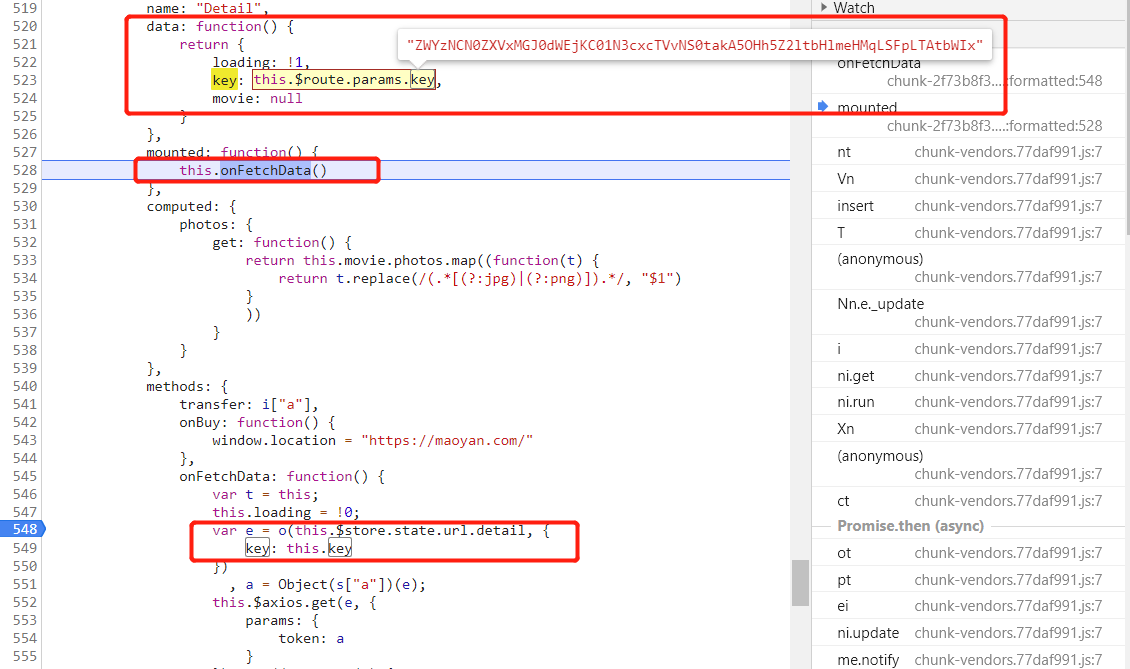
可以看到在计算 token 时 URL 已经被计算好了,然后网上看,正好 URL 的值来自于 e 这个变量,e 的值来自于 o 这个函数,OK,重新下断点,刷新页面。
![]()
![]()
![]()
断下,但是看样子 o 函数只是格式化了 key 参数,key 是在之前就计算好了,这里并没有计算 key 的流程,看了下其他的调用栈,应该是 vue 被混淆之后的样子,太乱了,此路不通,换条路走。
既然 key 是提前计算好的,那么全局搜索 key,看看是在哪个函数中给 key 赋值的。
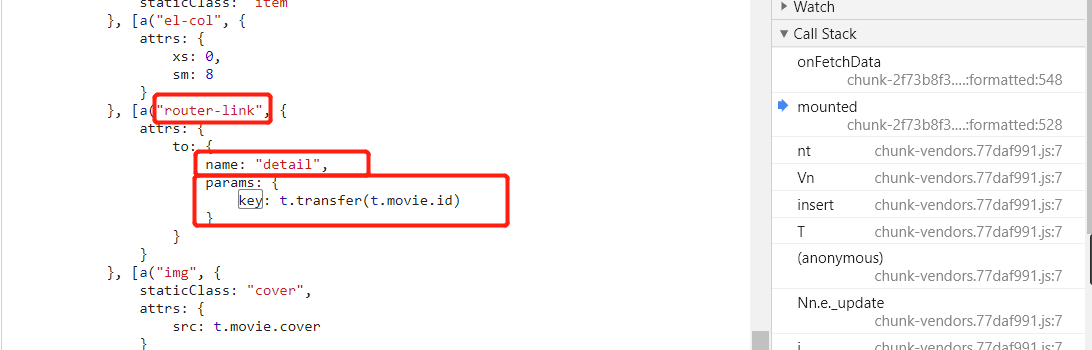
![]()
一共 9 个匹配,挨个找也不多,其他的都排除掉了,找到了这个,熟悉的 router-link(这不是 vue 中生成 a 标签方法嘛),熟悉的 detail(URL 中包含这个字符串),熟悉的 key,应该是它没错了,下断点,刷新页面。
![]()
传入了当前电影的 id 值,因为我点击的是第一个电影,所以它的 id 是 1,单步步入。
![]()
加密方式一目了然,这串乱码竟然是硬编码进去的,哈哈,很坑有木有。所以加密方式就是这串硬编码的字符串加上电影的 id 然后使用 base64 编码即可。
好了, 两个加密方法都分析好了,可以写代码了,完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| class SPA2Spider(scrapy.Spider):
name = "spa2"
@staticmethod
def sign(url, a):
t = str(int(time.time()))
s = ','.join([url, str(a), t])
return base64.b64encode(','.join([sha1(s.encode()).hexdigest(), t]).encode()).decode()
def start_requests(self):
for a in range(0, 100, 10):
token = self.sign("/api/movie", (((a + 10) // 10) - 1) * 10)
yield scrapy.Request(
url=f'http://spa2.scrape.center/api/movie/?limit=10&offset={a}&token={token}',
callback=self.parse)
def parse(self, response, **kwargs):
result = response.json()
for a in result['results']:
item = SPA2Item()
item['title'] = a['name'] + a['alias']
item['fraction'] = a['score']
item['country'] = '、'.join(a['regions'])
item['time'] = a['minute']
item['date'] = a['published_at']
s = 'ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb'
detail = base64.b64encode((s + str(a["id"])).encode()).decode()
yield Request(url=response.urljoin(f'/api/movie/{detail}/?token={self.sign(f"/api/movie/{detail}", 0)}'),
callback=self.parse_person,
meta={'item': item})
def parse_person(self, response):
result = response.json()
item = response.meta['item']
item['director'] = result['directors'][0]['name']
yield item
|
完整代码详见https://github.com/libra146/learnscrapy/tree/spa2
spa3
spa3 说明如下:
电影数据网站,无反爬,数据通过 Ajax 加载,无页码翻页,下拉至底部刷新,适合 Ajax 分析和动态页面渲染爬取。
无加密,无反爬,但是也没有页码,也就是说不能直接构造好所有的起始 URL,要在爬取的过程中去计算,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| class SPA3Spider(scrapy.Spider):
name = "spa3"
offset = 0
url = 'https://spa3.scrape.center/api/movie/?limit=10&offset=%s'
def start_requests(self):
urls = [self.url % self.offset]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
result = response.json()
for a in result['results']:
if a['id'] > result['count']:
continue
item = SPA3Item()
item['title'] = a['name'] + a['alias']
item['fraction'] = a['score']
item['country'] = '、'.join(a['regions'])
item['time'] = a['minute']
item['date'] = a['published_at']
yield Request(url=response.urljoin(f'/api/movie/{a["id"]}/'), callback=self.parse_person,
meta={'item': item})
if self.offset < result['count']:
self.offset += 10
yield Request(url=self.url % self.offset, callback=self.parse)
def parse_person(self, response):
result = response.json()
item = response.meta['item']
item['director'] = result['directors'][0]['name']
yield item
|
由于没有页码,所以起始 URL 的偏移只能从 0 开始,根据 limit 逐渐增大,停止条件就是偏移量大于响应中的 count 字段的值。其他的逻辑和 spa1 是一样的,不多说。
完整代码详见https://github.com/libra146/learnscrapy/tree/spa3
spa4
spa4 说明如下:
新闻网站索引,无反爬,数据通过 Ajax 加载,无页码翻页,适合 Ajax 分析和动态页面渲染抓取以及智能页面提取分析。
spa4 和 spa3 基本上的逻辑是一致的,只是爬取内容不一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class SPA4Spider(scrapy.Spider):
name = "spa4"
offset = 0
limit = 100
url = f'https://spa4.scrape.center/api/news/?limit={limit}&offset=%s'
def start_requests(self):
urls = [self.url % self.offset]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
result = response.json()
print(response.url)
for a in result['results']:
item = SPA4Item()
item['code'] = a['code']
item['published_at'] = a['published_at']
item['title'] = a['title']
item['updated_at'] = a['updated_at']
item['url'] = a['url']
item['website'] = a['website']
yield item
if int(result['count']) > self.offset:
self.offset += self.limit
yield Request(url=self.url % self.offset, callback=self.parse)
|
由于 spa4 数据量太大,这里为了学习就不全部爬取了,点到为止。
完整代码详见https://github.com/libra146/learnscrapy/tree/spa4
spa5
spa5 说明如下:
图书网站,无反爬,数据通过 Ajax 加载,有翻页,适合大批量动态页面渲染抓取。
图书网站,需要爬取的内容又不一样了,需要新建一个新的 item,其他的内容和上面的爬取方法是一致的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| class SPA5Spider(scrapy.Spider):
name = "spa5"
offset = 0
limit = 18
url = f'https://spa5.scrape.center/api/book/?limit={limit}&offset=%s'
def start_requests(self):
urls = [self.url % self.offset]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response, **kwargs):
result = response.json()
print(response.url)
for a in result['results']:
item = SPA5Item()
item['title'] = a['name']
item['author'] = '/'.join(a['authors'] or [])
yield Request(url=f'https://spa5.scrape.center/api/book/{a["id"]}/', callback=self.parse2,
meta={'item': item})
if int(result['count']) > self.offset:
self.offset += self.limit
yield Request(url=self.url % self.offset, callback=self.parse)
def parse2(self, response):
item = response.meta['item']
result = response.json()
item['price'] = result['price'] or 0
item['time'] = result['published_at']
item['press'] = result['publisher']
item['page'] = result['page_number']
item['isbm'] = result['isbn']
yield item
|
先从基本数据中记录下 title 和 author,然后再进入到详细信息页面获取到书本的其他信息,最后存储到数据库。
完整代码详见https://github.com/libra146/learnscrapy/tree/spa5
spa6
spa6 说明如下:
电影数据网站,数据通过 Ajax 加载,数据接口参数加密且有时间限制,源码经过混淆,适合 JavaScript 逆向分析。
经过分析及测试,sp6 和 spa2 貌似是一样的接口,直接使用 spa2 的代码就可以获取到数据,所以就不重复写了。🤣🤣不知道为什么会这样,目前来说我还没发现有什么区别,如果有知道的小伙伴可以告诉我。
总结
这六个网站相比上一篇文章难度稍微高了一点,涉及到了 Ajax 接口和 JS 逆向,可以借此学习到逆向相关知识和 JS 调试技巧。
参考链接
https://docs.scrapy.org/en/latest/index.html
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):![LLLibra146]()
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
本文链接:
https://blog.d77.xyz/archives/186911b0.html