JS逆向实战:如何利用httpx与Scrapy突破HTTP2协议
引言
大家好,还是原来的爬虫练习平台,本篇文章来分享一下 HTTP2 协议的请求方法。
spa16
spa16 地址:https://spa16.scrape.center/
spa16 说明:
图书网站,无反爬,不同于其他,该网站协议采用 HTTP 2, 适合用于 HTTP 2协议分析和测试
看说明无反爬,只是使用了 HTTP2 协议,那我们使用 requests 就不行了,查看了几个 issues,#5757,#5506,#4604,看来它短时间内是不支持 HTTP2 协议的,还得找个替代品才能完成我们的需求了。
httpx
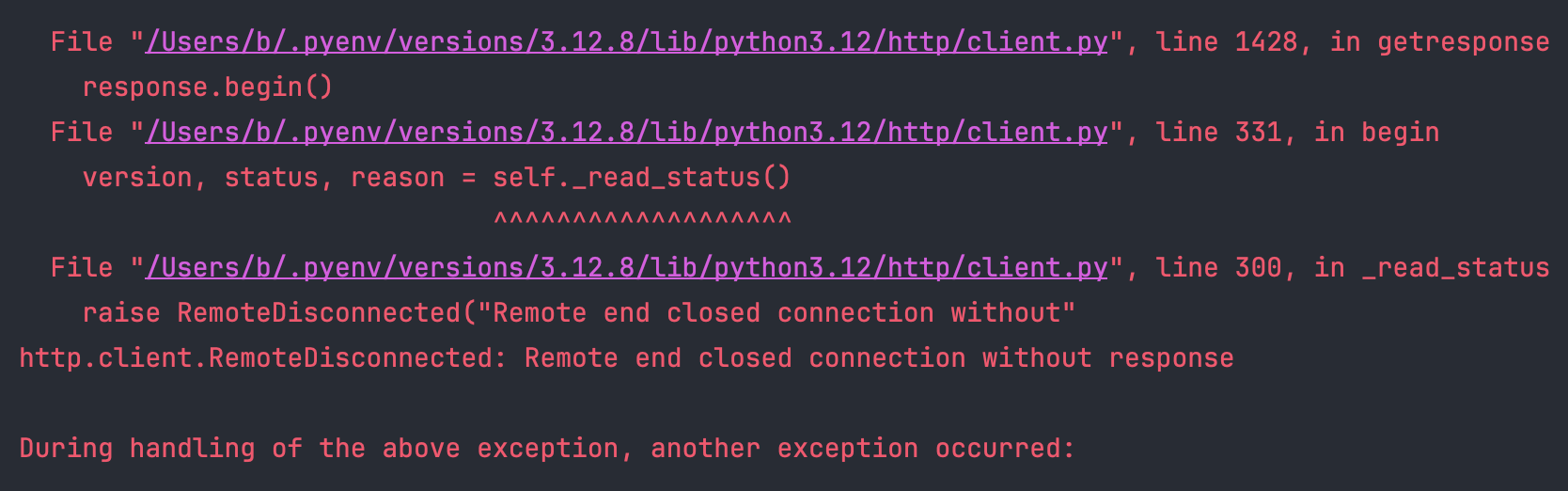
如果使用 requests 发送请求到仅支持 HTTP2 的服务端,会有如下报错:
1 | import time |
此时,我们需要使用替代方案,HTTPX 是一个功能齐全的 Python 3 HTTP 客户端库。它包含一个集成的命令行客户端,支持 HTTP/1.1 和 HTTP/2,并提供同步和异步 API。
httpx 相比于 requests,不仅拥有 requests 的所有功能,也能通过拓展的方式支持下列 requests 不支持的功能:
- HTTP2 协议
- 可以提供异步支持
- 支持命令行客户端
- 解码 brotli 压缩
- SOCKS 代理支持
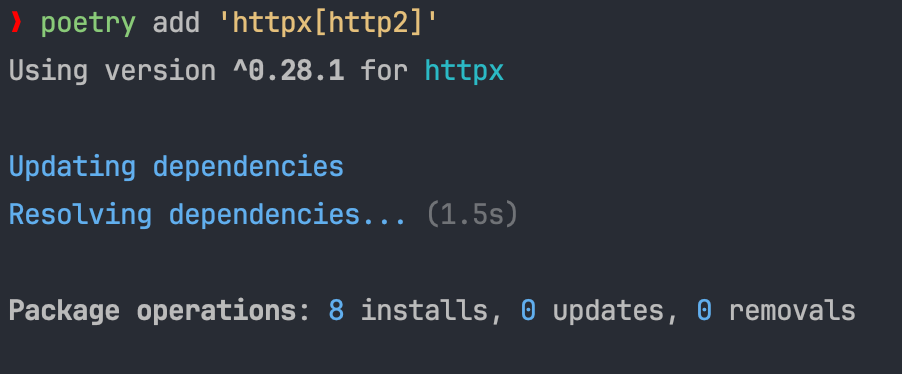
我使用的是 poetry 包管理工具,安装它,会有下面的报错,查了一下,是因为 poetry 将方括号解释为特殊字符了,加上引号就可以正常安装了。

安装后,修改代码,新建一个支持 HTTP2 协议的客户端,然后调用 get 方法即可。
1 | import time |
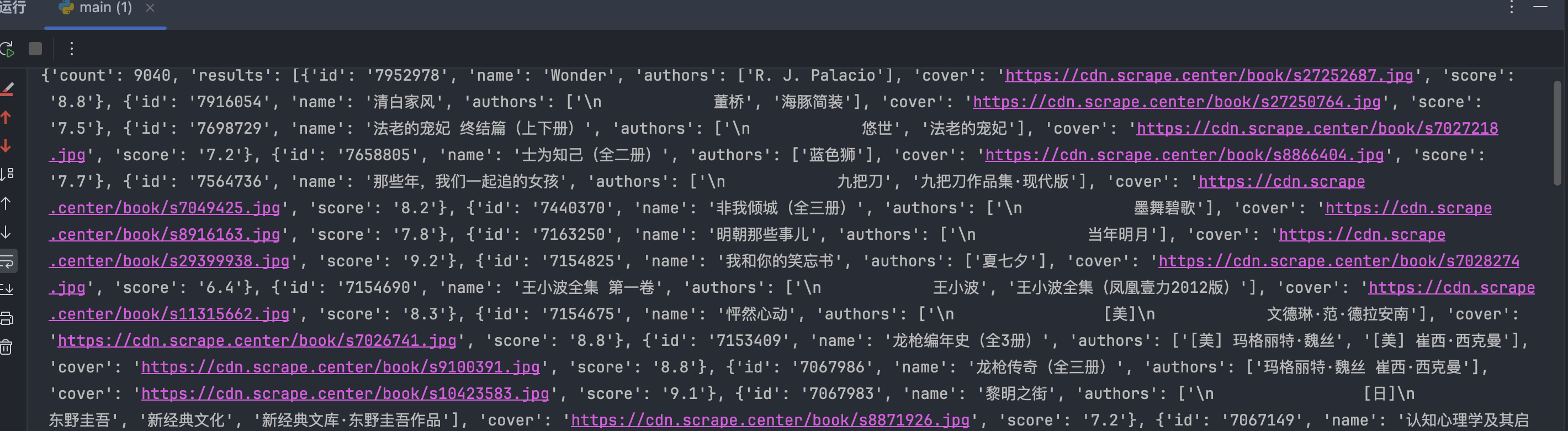
可以正常获取到数据。
hyper
hyper 是使用纯 Python 实现的支持 HTTP2 协议的 Python 客户端,不过它已经停止更新了,这里就不多介绍了。
Scrapy
可能有小伙伴问了,那如果使用 Scrapy 的时候,如何支持 HTTP2 协议呢?其实这个问题你想到了,官方也想到了,我们只需要看看官方文档即可知道原来 Scrapy 是支持 HTTP2 协议的!
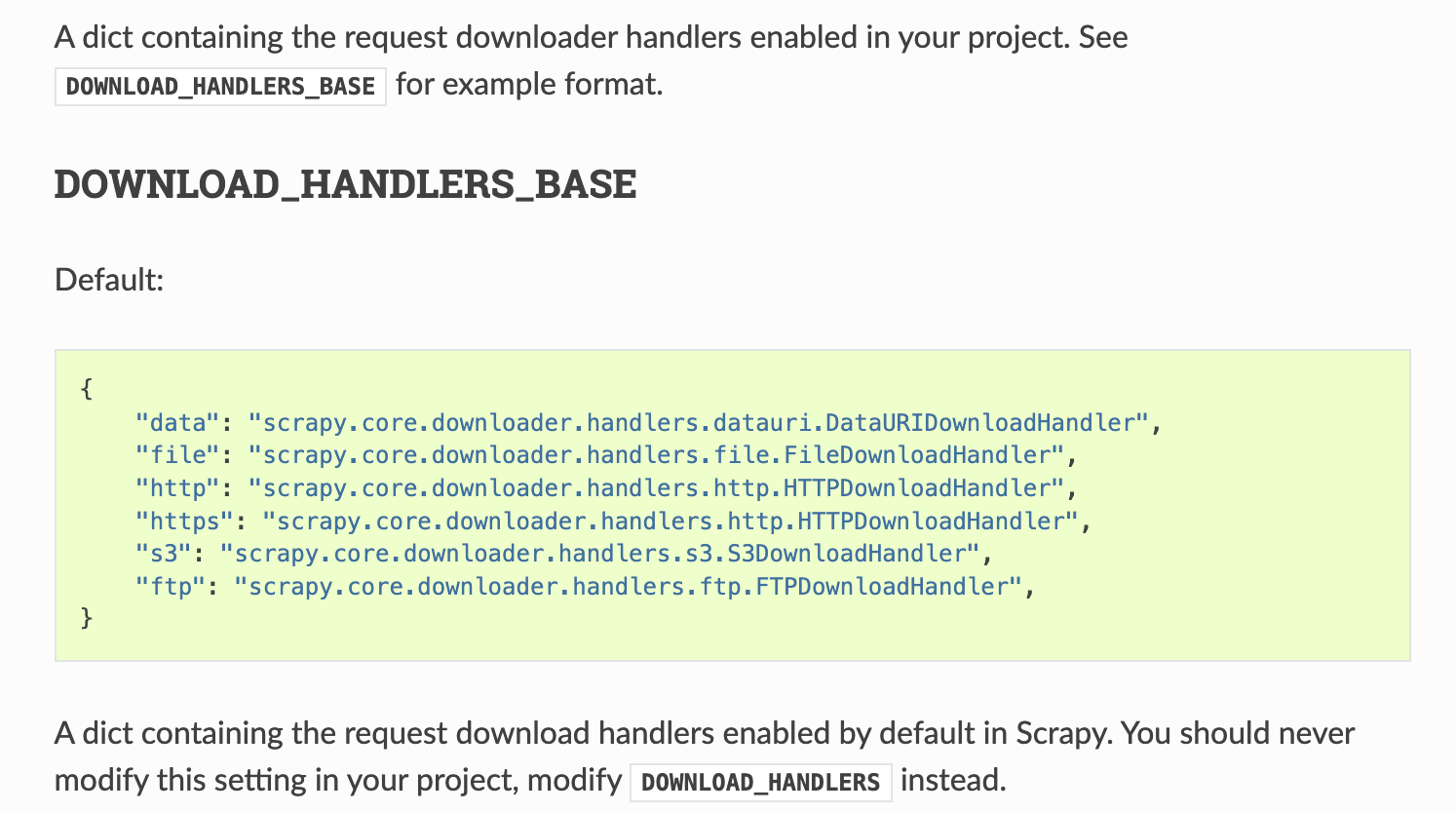
查看 Scrapy 的官方文档,可以看到默认情况下,每种协议都有自己的默认处理器,HTTP 协议处理器默认值使用的是 HTTPDownloadHandler,但是如果想要支持 HTTP2 协议的话,只需要在设置文件中覆盖默认的 HTTP 处理器即可。

并且要安装 Twisted[http2]>=17.9.0 后才能支持 HTTP2 协议,并且当前版本的 HTTP2 协议实现有一些限制,不过对于爬虫来说,应该没有太大影响。
现在我们新建一个爬虫 spa16 来尝试一下 Scrapy 的 HTTP2 协议支持是否可以正常爬到刚才的数据。
使用命令新建一个 spa16 爬虫:
1 | scrapy genspider demo "https://spa16.scrape.center/api/book/?limit=18&offset=0" |
在生成的 spa16.py 中,添加以下代码:
1 | import scrapy |
由于这里是为了验证 HTTP2 协议的可用性,就不写后续的解析存储的代码了。别忘了安装对应的依赖库:poetry add 'Twisted[http2]'。
在 settings.py 文件中添加设置覆盖默认的 https 下载处理器:
1 | DOWNLOAD_HANDLERS = { |
启动 spa16 爬虫,查看输出结果,可以看到,正常打印了响应,至此可以确认,Scrapy 是支持 HTTP2 协议的!
最终代码详见:https://github.com/libra146/learnscrapy/commit/1cca6db68e02fca3d58e81c093ed319812c691e6
总结
HTTP2 协议现在已经比较普遍了,Python 支持 HTTP2 协议的库不是很多,但是目前有 httpx 和 Scrapy 基本上够用了,同时还有一些其他封装的 curl 或者 go 实现的支持 HTTP2 协议的库可以满足更多的需求,例如更改 tls 指纹等,这里就不多说了,感兴趣的小伙伴可以自行搜索尝试一下。
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
