import scrapy from scrapy_selenium import SeleniumRequest from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC
classAntiSpider(scrapy.Spider): name = 'antispider1'
defstart_requests(self): urls = ['https://antispider1.scrape.center/'] for a in urls: yield SeleniumRequest(url=a, callback=self.parse, wait_time=8, wait_until=EC.presence_of_element_located( (By.CLASS_NAME, 'm-b-sm')))
driver_options = driver_options_klass() if browser_executable_path: driver_options.binary_location = browser_executable_path for argument in driver_arguments: driver_options.add_argument(argument)
classAntiSpider(scrapy.Spider): name = 'antispider1'
defstart_requests(self): urls = ['https://antispider1.scrape.center/'] for a in urls: yield SeleniumRequest(url=a, callback=self.parse, wait_time=3, wait_until=EC.presence_of_element_located( (By.CLASS_NAME, 'm-b-sm')))
classAntiSpider(scrapy.Spider): name = 'antispider3'
defstart_requests(self): urls = ['https://antispider3.scrape.center/'] for a in urls: yield SeleniumRequest(url=a, callback=self.parse, wait_time=3, wait_until=EC.presence_of_element_located( (By.CLASS_NAME, 'm-b-sm')))
defparse(self, response, **kwargs): result = response.xpath('//div[@class="el-card__body"]') for a in result: item = Antispider3ScrapyItem() chars = {} # 有反爬 if r := a.xpath('.//h3[@class="m-b-sm name"]//span'): for b in r: chars[b.xpath('.//@style').re(r'\d\d?')[0]] = b.xpath('.//text()').get().strip() # 先用sorted函数来排序,使用lambda指定索引值为0的值,也就是根据key值来排序,排序后使用zip函数来将所有的字符串放到 # 同一个元组中,list函数用来将生成器转成列表,之后使用索引值选择title所在的元组,使用join函数连接所有的字符串即为标题字符串 item['title'] = ''.join(list(zip(*sorted(chars.items(), key=lambda i: i[0])))[1]) else: # 没有反爬 item['title'] = a.xpath('.//h3[@class="name whole"]/text()').get() item['author'] = a.xpath('.//p[@class="authors"]/text()').get().strip() url = a.xpath('.//a/@href').get() print(response.urljoin(url)) yield SeleniumRequest(url=response.urljoin(url), callback=self.parse_person, meta={'item': item}, wait_time=3, wait_until=EC.presence_of_element_located((By.CLASS_NAME, 'm-b-sm')))
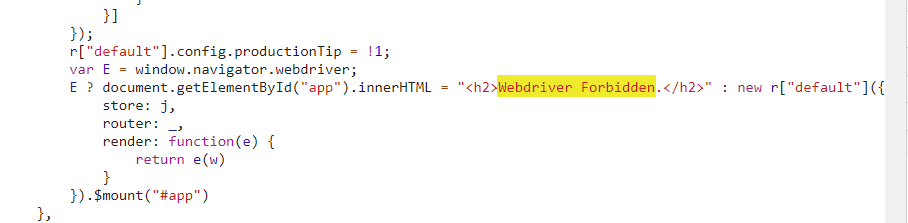
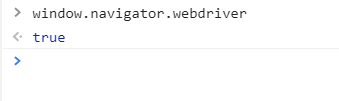
classAntiSpider(scrapy.Spider): name = 'antispider4' css = {}
defstart_requests(self): urls = ['https://antispider4.scrape.center/css/app.654ba59e.css'] for a in urls: # 解析css yield Request(url=a, callback=self.parse_css)
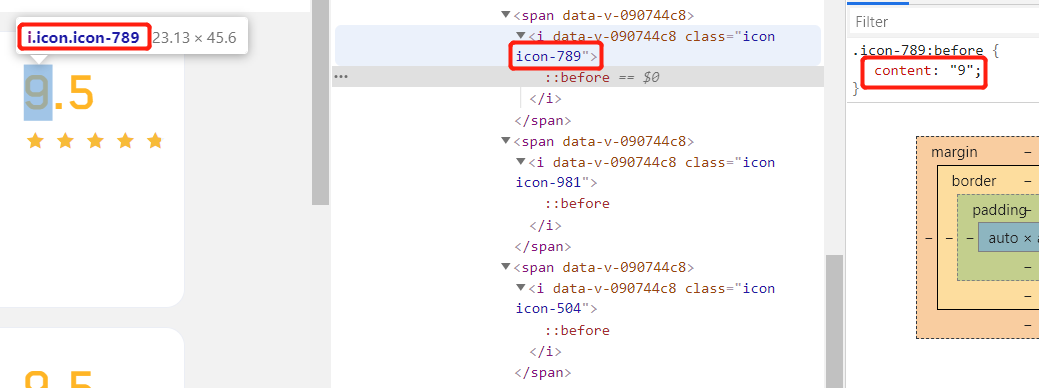
defparse_css(self, response): # 根据规律使用正则找到所有需要用到的属性,由于这里只反爬了分数,所以只需要匹配少量的数字和点即可。 result = re.findall(r'\.(icon-\d*?):before{content:"(.*?)"}', response.text) for key, value in result: self.css[key] = value print(self.css) # 访问主页 yield SeleniumRequest(url='https://antispider4.scrape.center/', callback=self.parse_data, wait_time=3, wait_until=EC.presence_of_element_located((By.CLASS_NAME, 'm-b-sm')))
defparse_data(self, response): result = response.xpath('//div[@class="el-card item m-t is-hover-shadow"]') for a in result: item = Antispider4ScrapyItem() item['title'] = a.xpath('.//h2[@class="m-b-sm"]/text()').get() if r := a.xpath('.//p[@class="score m-t-md m-b-n-sm"]//i'): item['fraction'] = ''.join([self.css.get(b.xpath('.//@class').get()[5:], '') for b in r]) item['country'] = a.xpath('.//div[@class="m-v-sm info"]/span[1]/text()').get() item['time'] = a.xpath('.//div[@class="m-v-sm info"]/span[3]/text()').get() item['date'] = a.xpath('.//div[@class="m-v-sm info"][2]/span/text()').get() url = a.xpath('.//a[@class="name"]/@href').get() print(response.urljoin(url)) yield SeleniumRequest(url=response.urljoin(url), callback=self.parse, meta={'item': item}, wait_time=3, wait_until=EC.presence_of_element_located((By.CLASS_NAME, 'm-b-sm')))