JS逆向实战:前端渲染
引言
还是原来的爬虫练习平台,我看比我之前写博客的时候更新了一些前端渲染的内容,本文的重点是 JS 逆向中的前端渲染。
spa7
spa7 地址:https://spa7.scrape.center/
spa7 说明如下:
NBA 球星数据网站,数据纯前端渲染,Token 经过加密处理,适合基础 JavaScript 模拟分析。
打开浏览器的网络标签页,查看网络请求。
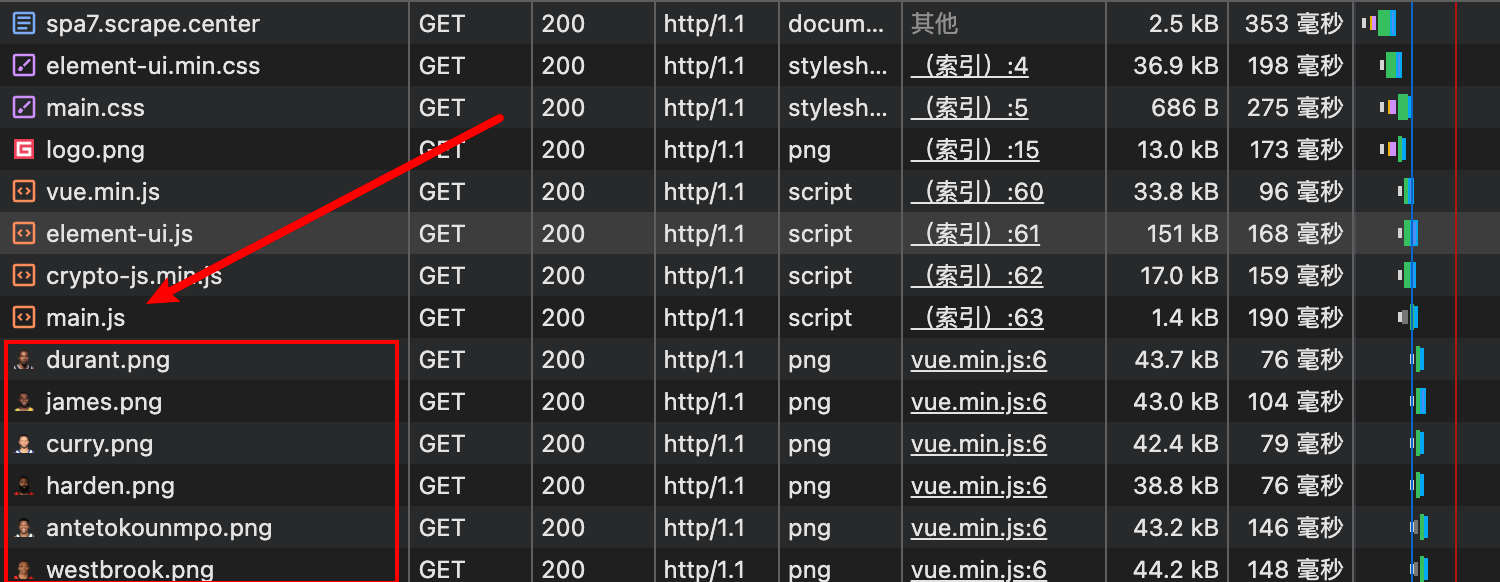
发现在 main.js 后面就开始加载图片了,细想一下,只有在获取到了球星的数据之后,才能通过数据拿到对应的图片地址,然后加载图片,那么我们可以大胆猜测,main 这个 js 里面大概率就是我们需要的数据。
打开它看看:
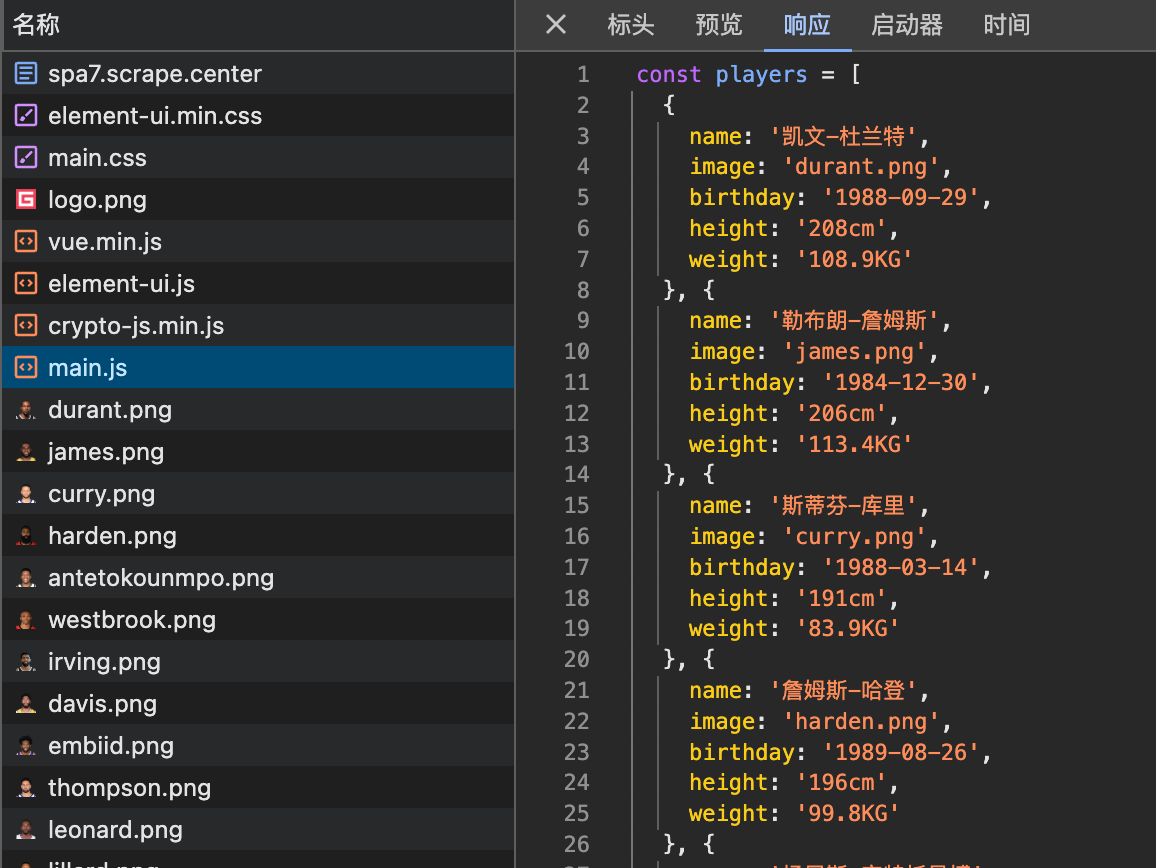
猜对了,里面的确是我们想要的数据,那么获取它的数据就简单了,直接请求这个 js 就可以了,虽然这个说明中提到了 token 加密,但是我实际上没有发现 token 有关的内容,这里就先忽略吧。
至于请求 js 如何拿到数据,很简单,正则表达式,或者本地执行 js 或者其他方案都可以,只要能拿到数据即可,我这里使用正则的方案。顺便推荐一个好用的正则表达式测试网站,可以很方便的调试正则表达式,再也不用一步步断点调试了。
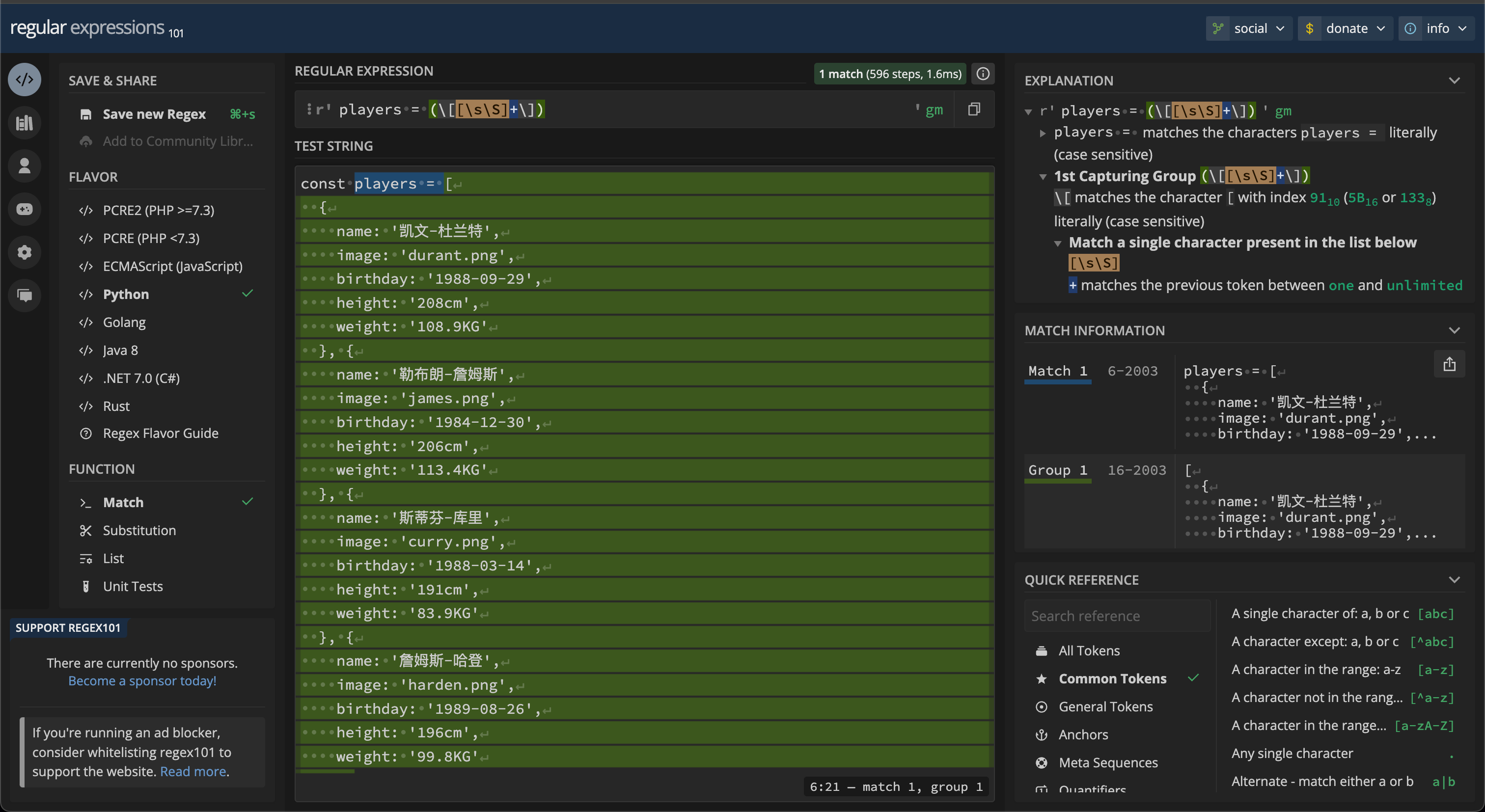
上代码:
1 | import json |
详细代码可以看 Github:https://github.com/libra146/learnscrapy/tree/main/js
spa8
spa8 说明:
NBA 球星数据网站,数据纯前端渲染,Token 经过加密处理,JavaScript 代码一行混入 HTML 代码,防止直接调试,适合 JavaScript 逆向分析。
查看网络请求,发现只是把 js 放到了 html 源码中,spa7 的代码可以复用,基本上不用改,所以这里就不重复写了。至于为什么说明中写了 js 只有一行,但是我看 js 是格式化好的,不知道为啥,暂时忽略它。
spa9
spa9 说明:
NBA 球星数据网站,数据纯前端渲染,Token 经过加密处理, JavaScript 经过 eval混淆,适合 JavaScript 逆向分析。
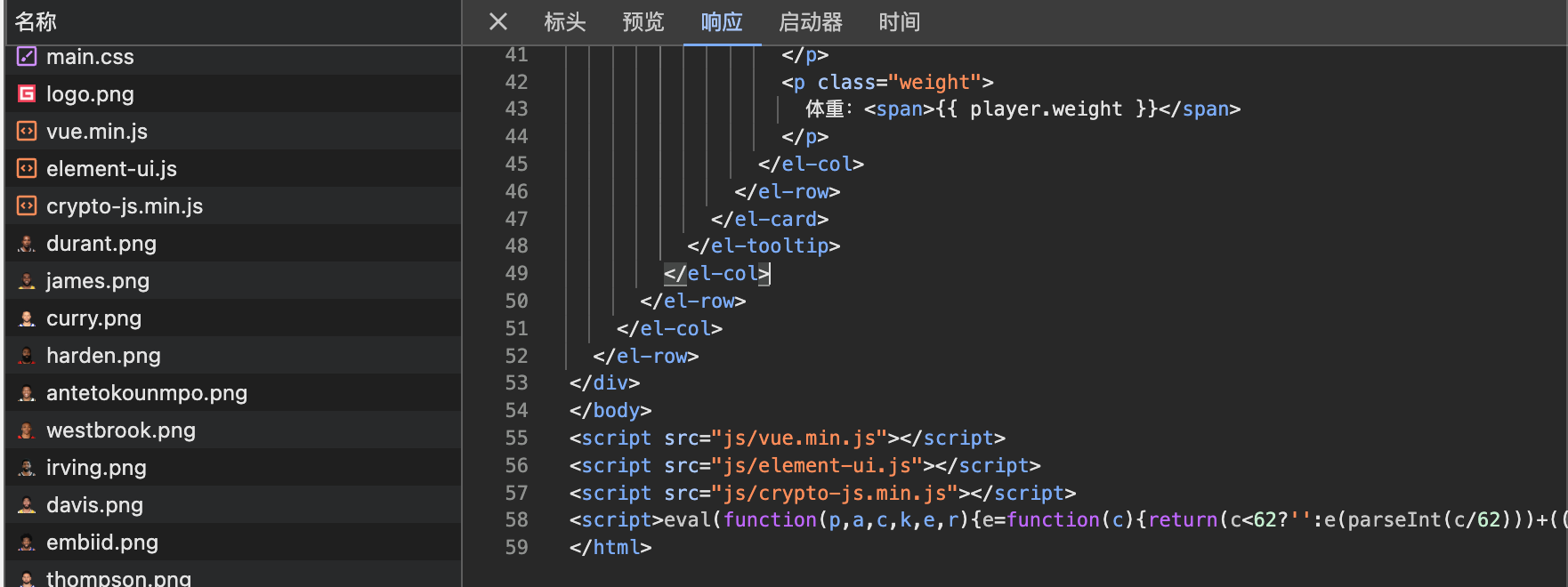
查看网络请求和 html 源代码,发现 js 数据的确被混淆了,先拿到 js 看看长什么样子:
1 | eval(function(p, a, c, k, e, r) { |
可以看到 eval 中就是一个 js 自执行函数,有好多参数,但是基本上可以看出来一些数据,看起来只是做了一些字符串变换的操作,简单调试一下看看。
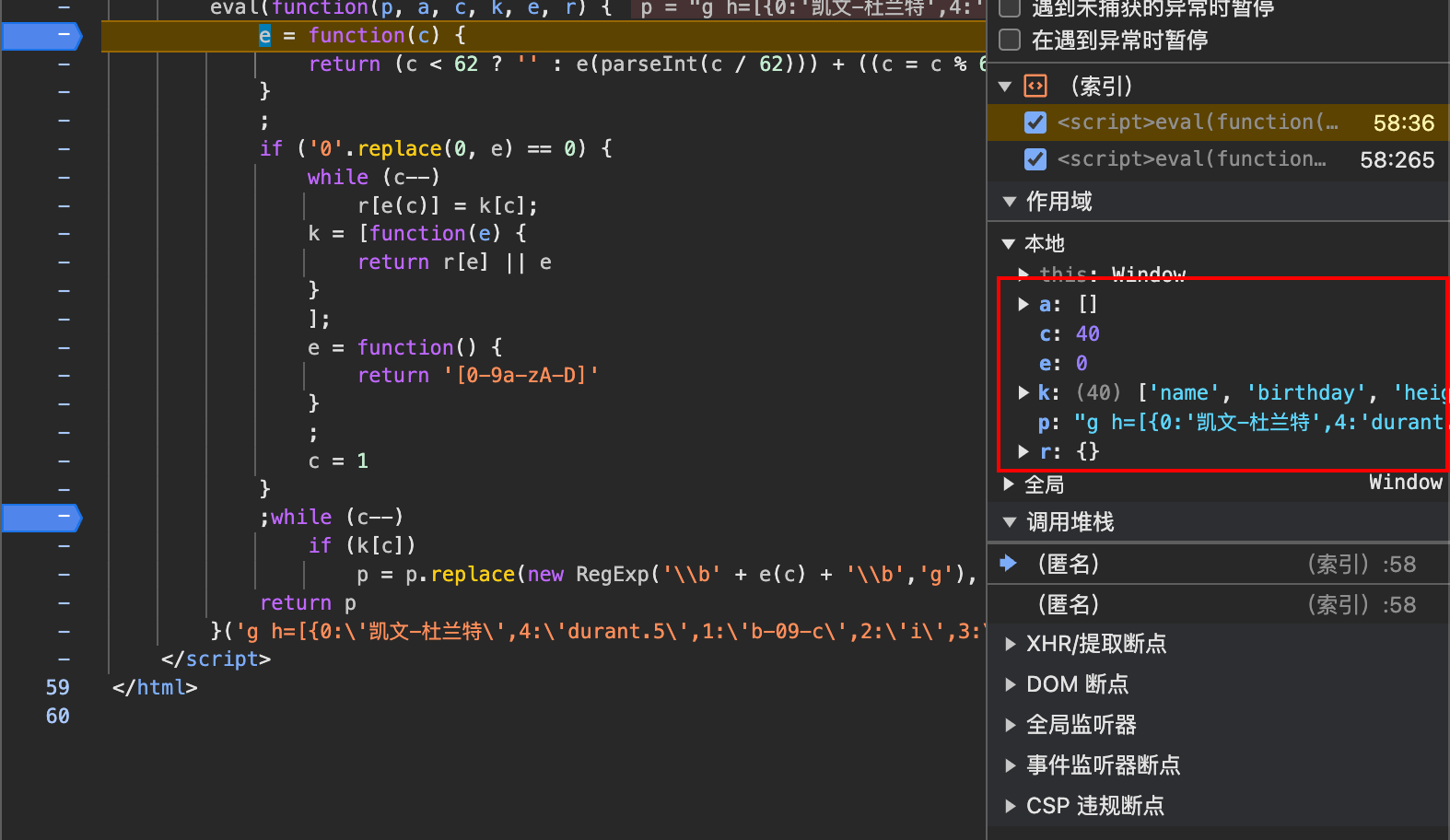
在第一行打个断点,可以看到函数的参数,整个函数有几个函数组成,单步走一下。
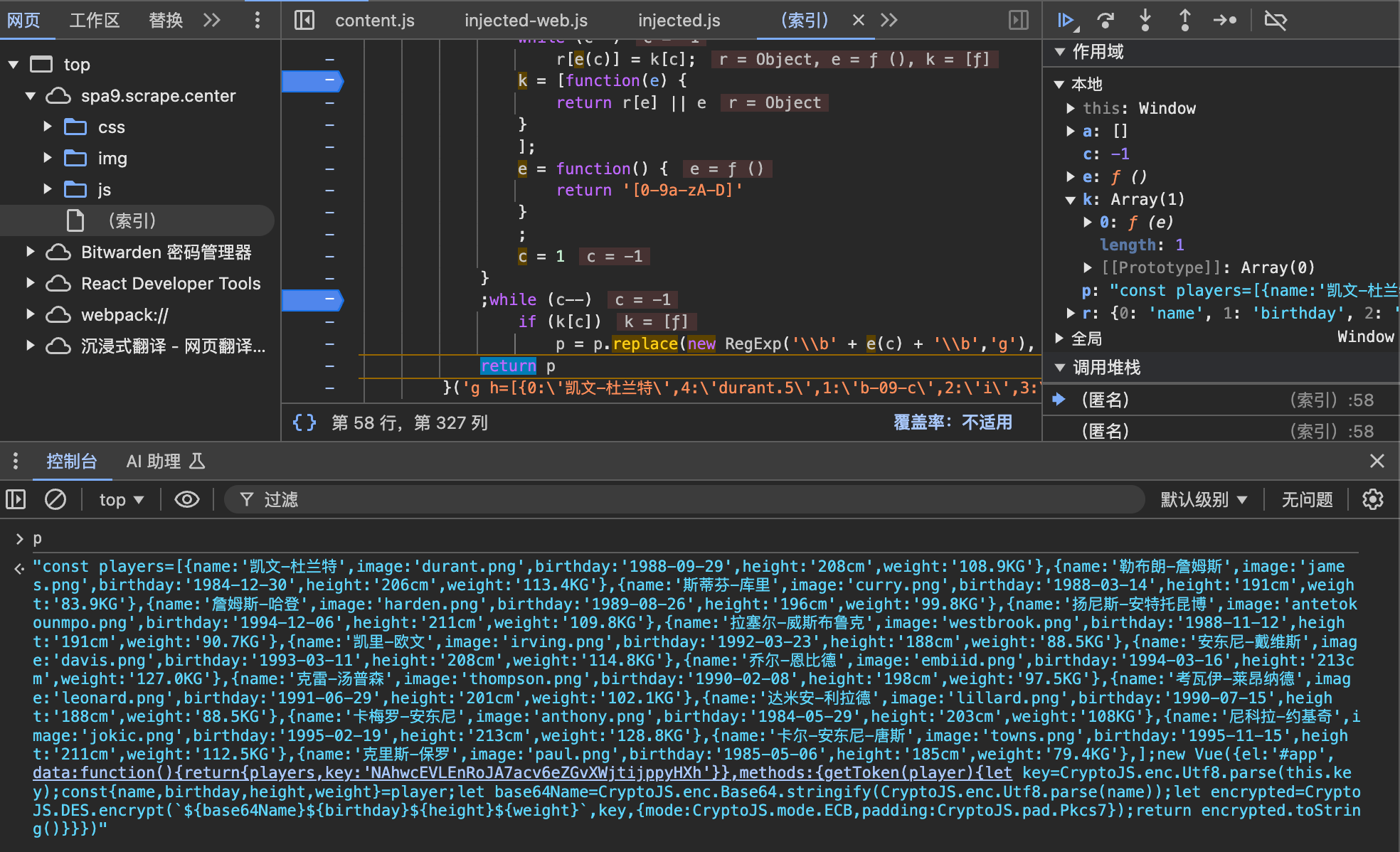
首先是定义了几个函数,看起来是对 r 变量进行填充,内容是通过 e 函数进行变换之后的内容,可以理解为解密或者解码。
解码完成以后,通过 replace 函数动态的替换单个字符,使用 r 变量的内容。
走到后面发现 p 变量就是之前我们看到的初始化的 js 代码了,这个 p 变量的内容会被当成 js 代码执行,流程就和之前是一样的了。但是要如何还原混淆过的字符串呢,我这里尝试使用 Python 来解码字符串试试。
1 | import json |
代码比较丑哈哈,因为要先将 eval 执行的 js 代码提取出来,然后使用 Python 方法来解码它,解码之后就是一堆 js 代码了,可以用 spa7 中的代码来提取数组内容,然后 json loads 加载遍历输出即可。
完整代码见:https://github.com/libra146/learnscrapy/tree/main/js
总结
这几个网站的难度不大,但是都比较繁琐,因为要使用正则的方式来各种提取 js 代码,还要使用 Python 重新实现 js 的解码函数,属实是比较难调试。不过这里可以考虑使用 AI,AI 可以将 js 代码直接翻译成 Python 代码,还是比较方便的。
或者可以直接使用 nodejs,可以更加方便的获取 js 执行的结果,不用使用正则提取数据了。
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
