JS逆向实战:AST技术破解移动数组混淆&&格式化检测
大家好,还是原来的爬虫练习平台,今天继续分享 AST 还原移动数组混淆。
antispider9
antispider9 地址:https://antispider9.scrape.center/
antispider9说明:
JavaScript 反爬,核心加密逻辑使用位置移动数组混淆,同时设置格式化保护,适合AST分析。
今天的混淆和上次的 OB 混淆很类似,大概看了一下代码,就是一个大数组+数组元素位移+格式化检测+字符串加密。
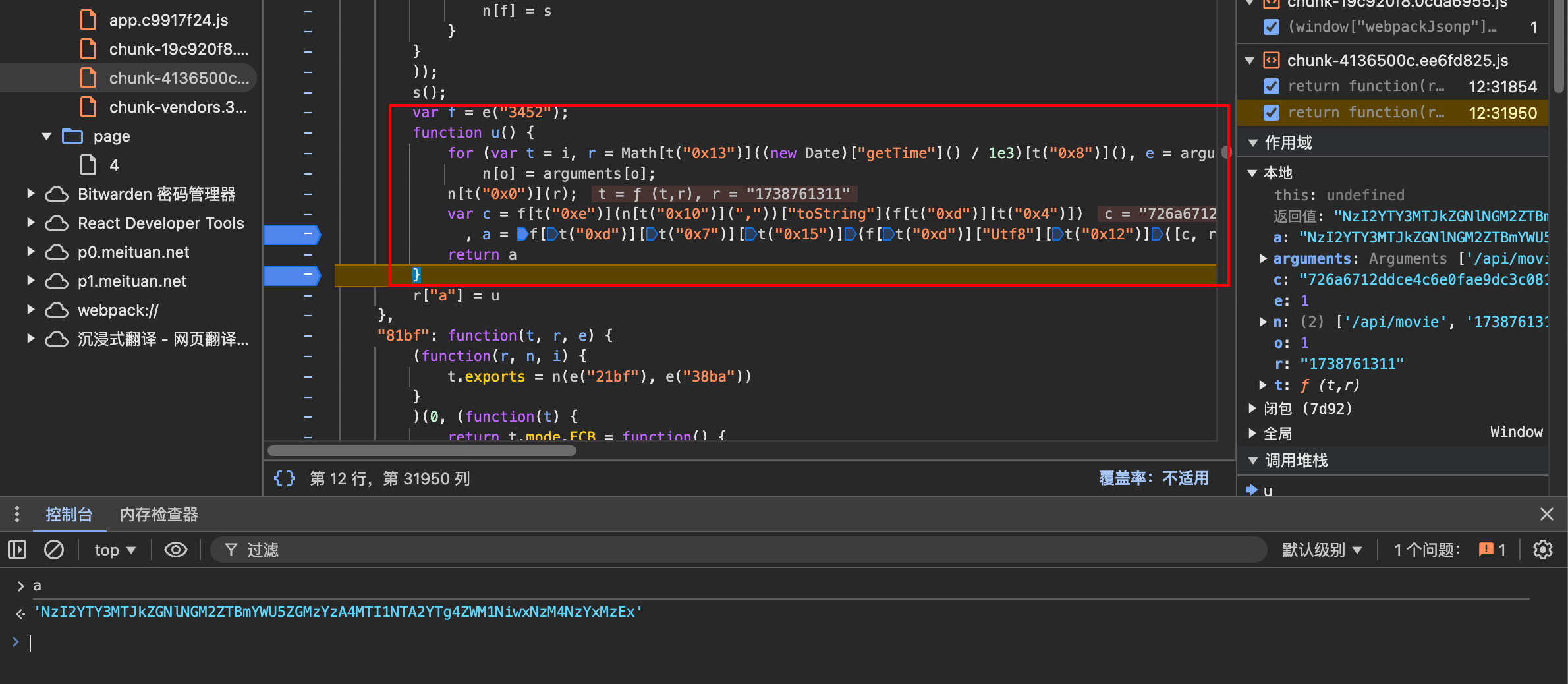
调试一下看看,发现被加密的字符串都有一个特征,调用了 t 函数并且参数是一个十六进制的字符串,接下来我们来找解密函数并且使用 AST 的方式将其还原。
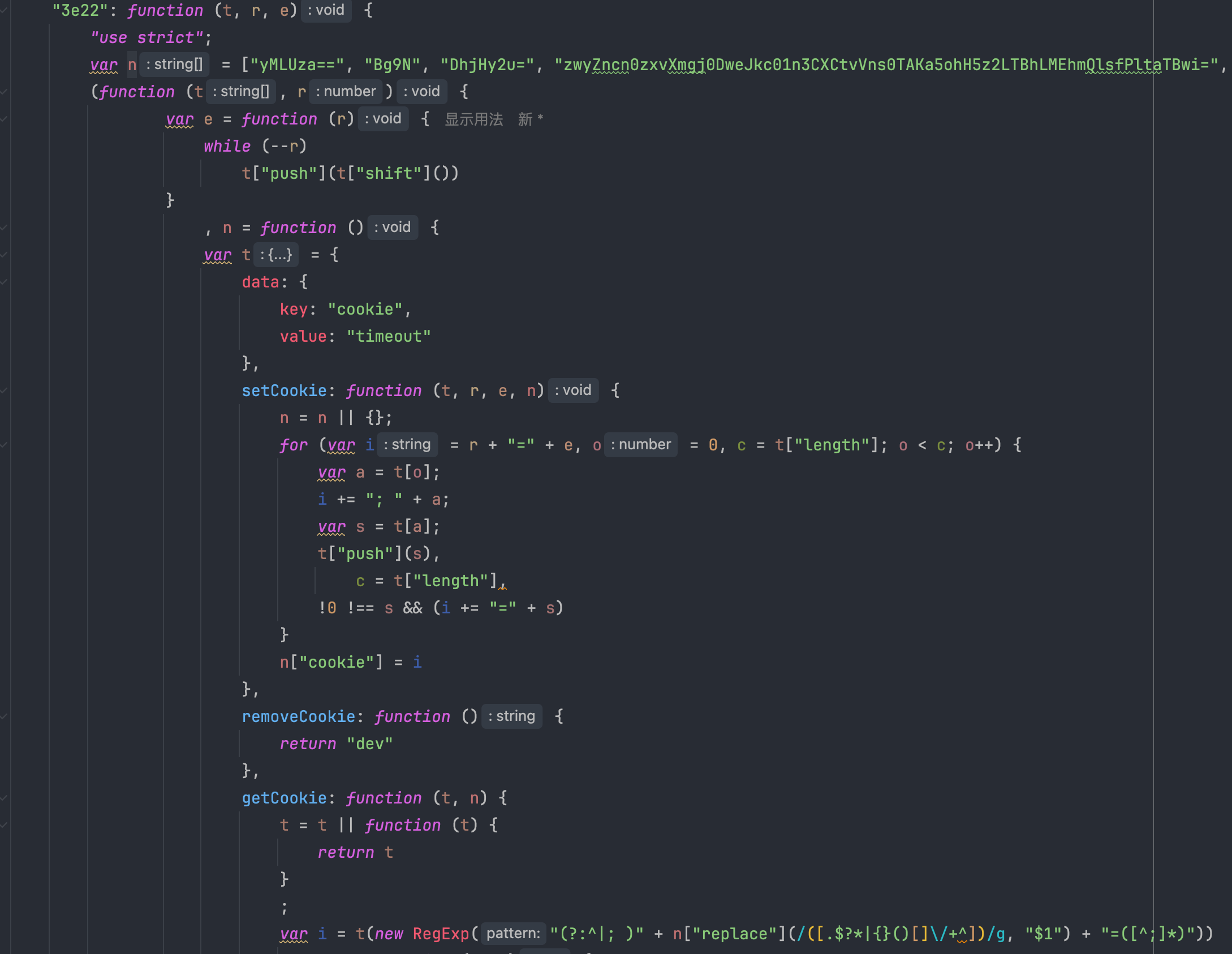
打个断点,发现一个大数组,数组运行后元素会偏移。下面可以看到一个正则表达式,大家注意看,基本上只要有正则表达式,很大可能性就是格式化检测了。
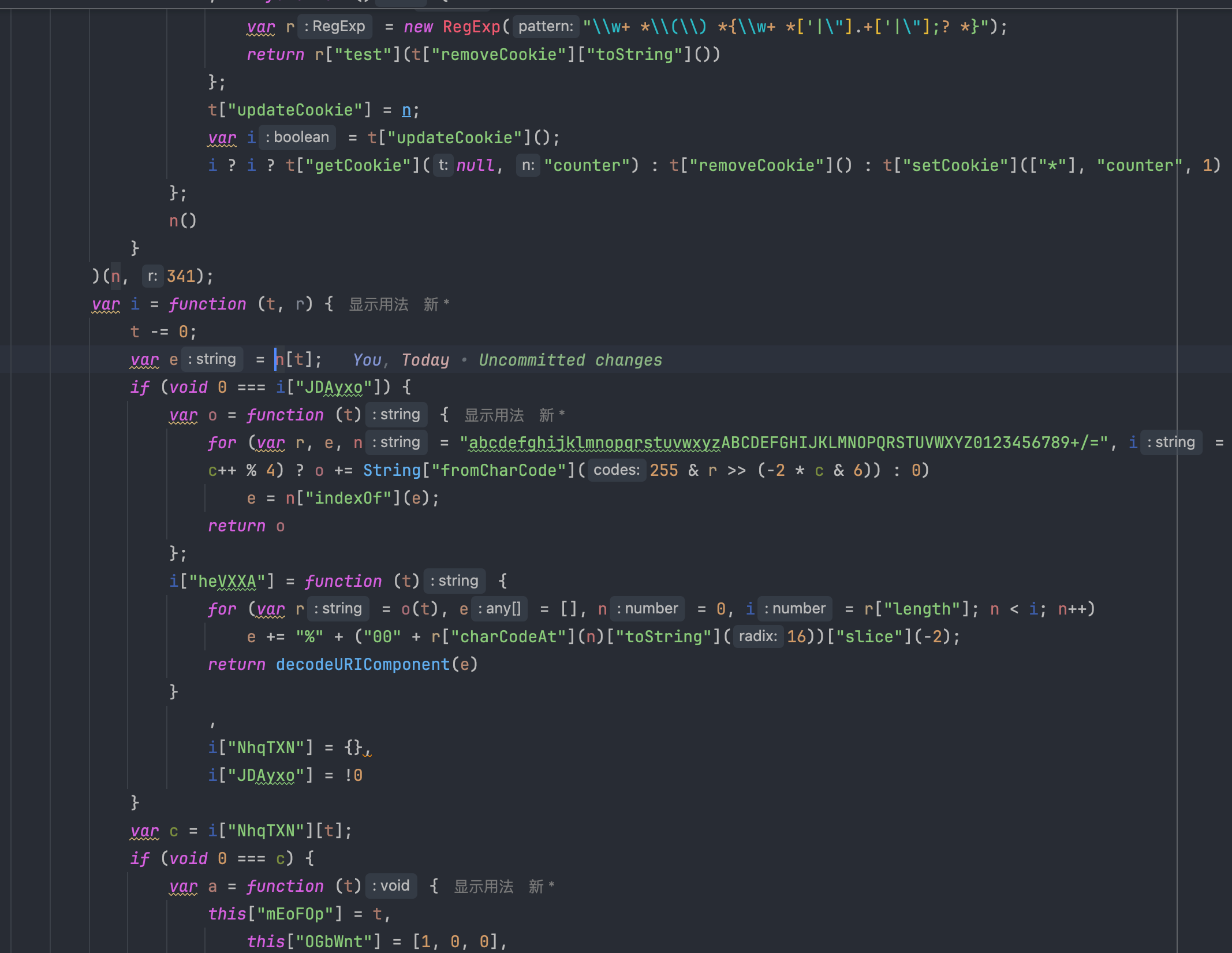
图片最上方的正则表达式,就是格式化检测无疑了。别看里面有很多更新 cookie 删除 cookie 的函数,其实都是无用的函数,用来混淆格式化检测代码的。这里面还有一个重要的函数,那就是 i 函数,最终我们定位到,i 就是字符串解密函数,我们可以将它抠出来,通过 AST 的方式来解密被加密后的字符串。
扣解密函数
现在我们新建一个 JS 文件,将解密函数抠出来, 将大数组补上,让解密函数可以正常运行,别忘了将格式化检测的代码去掉,至于如何去掉,这个比较看经验,基本的逻辑是看解密函数中比较重要的变量,在后续的逻辑中没有被用到,那基本上后续的流程都是可以去掉的。
如果遇到复杂的,无法一下子看出来的,也可以考虑先着重将涉及到正则的地方单步走一遍,然后再判断是否要去掉。实在不行,格式化检测一般都是检测某段代码的 toString 方法的结果和正则表达式是否能对得上,可以在关键的位置将 true 改成 false 或者将 false 改成 true 来跳过格式化检测。
1 | var n = ["qMfZzty0", "Dg9tDhjPBMC=", "y29UC3rYDwn0B3i=", "y29UC29Szq==", "E30Uy29UC3rYDwn0B3iOiNjLDhvYBIb0AgLZiIKOicK=", "CMv0DxjUicHMDw5JDgLVBIGPia==", "zw5J", "u0Hbmq==", "ChjVDg90ExbL", "AM9PBG==", "BgvUz3rO", "CgfYC2u=", "CM91BMq=", "zxjYB3i=", "C3rYAw5NAwz5", "xIHBxIbDkYGGk1TEif0RksSPk1TEif19", "DgvZDa==", "CMv0DxjUic8IicSGDgHPCYaRiciV", "ChvZAa==", "Aw5MBW==", "DgfIBgu=", "yMLUza==", "sgv4", "zxHJzxb0Aw9U", "x19WCM90B19F"]; |
我这里将两个格式化检测点的结果取了反,很简单,在检测结果前面加一个 ! 就可以了,这样既不用分析格式化检测的逻辑,只要找到对应的检测点即可过掉检测。
AST 反混淆
解密函数搞定以后,和之前的文章一样,只要找到对应的调用位置,对特定的函数获取到参数然后手动调用即可,代码可以复用一部分。别忘了解密函数特征:参数为字符串,并且是十六进制的数字。
1 | traverse(ast, { |
根据前面的思路,写出反混淆代码,看一下反混淆的结果:

现在的代码一目了然,使用了哪些函数一眼就可以看到了。看上去和之前的逻辑基本上是一样的,用到了 base64 和 sha1,但是还有一个 f 函数,目前不知道是做什么用的。
webpack 调用
f 函数就涉及到了 webpack 打包工具了,webpack 会将多个不同的 JS 打包成一个 JS 来方便加载,减少 HTTP 请求,通过不同的 loader 实现顺序加载按需加载等需求。webpack 中大量用到了自执行函数来实现此目的。
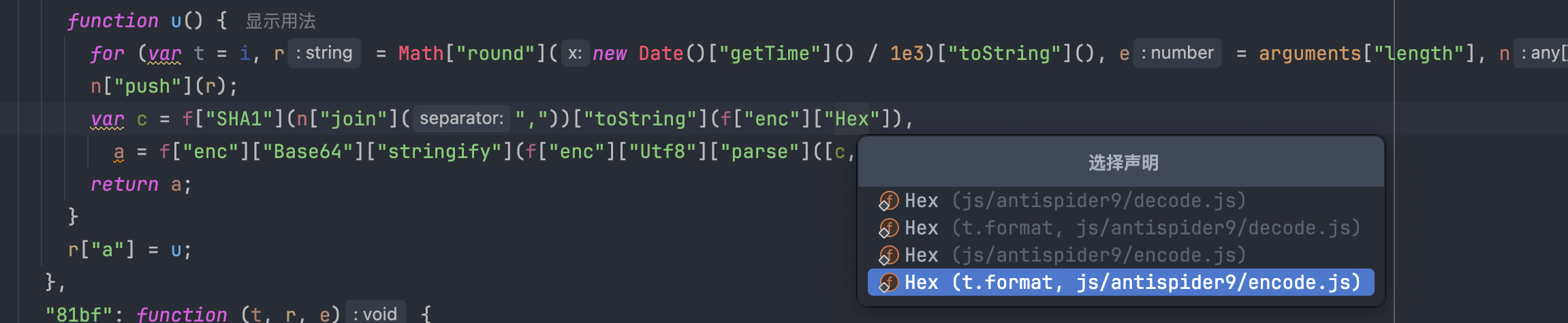
为了不费脑细胞,我们偷懒点可以直接按住 Ctrl 键然后点击对应的字符串,会直接出现声明,选择一个跳过去即可。
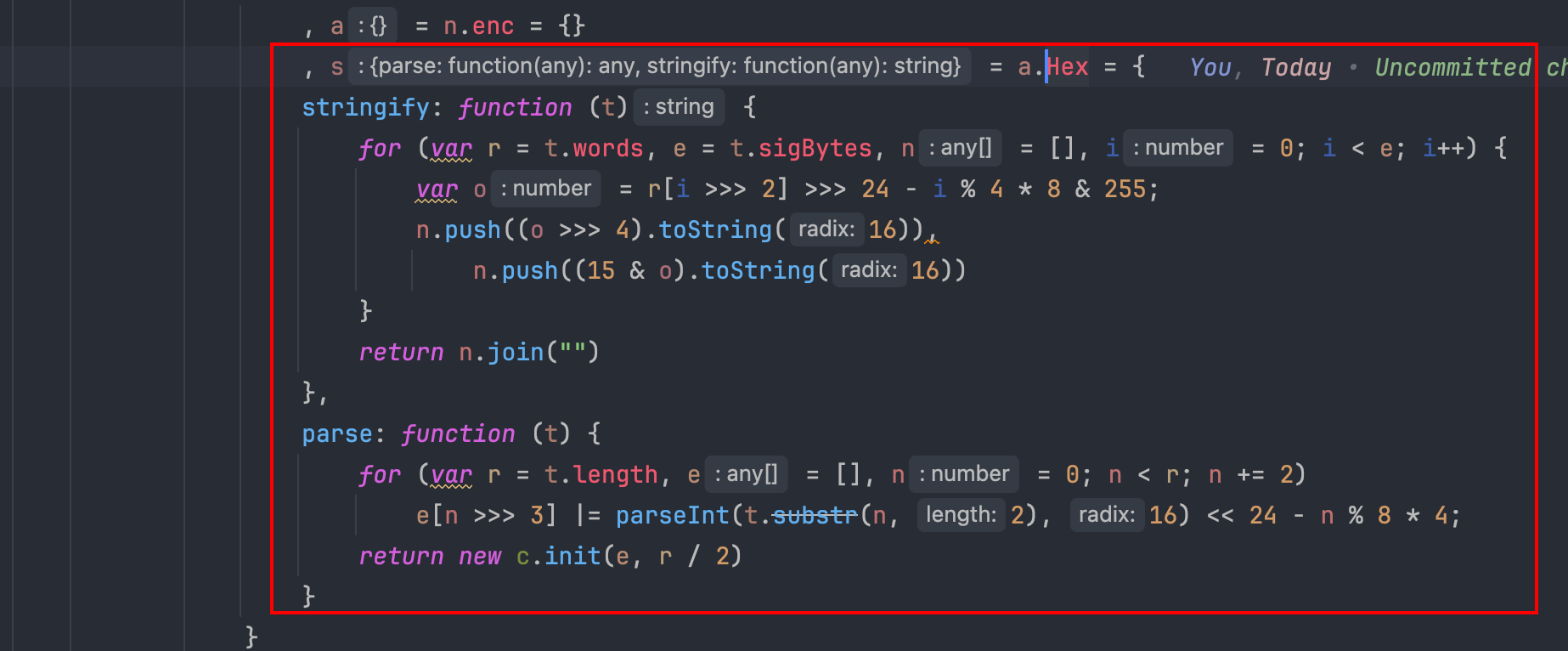
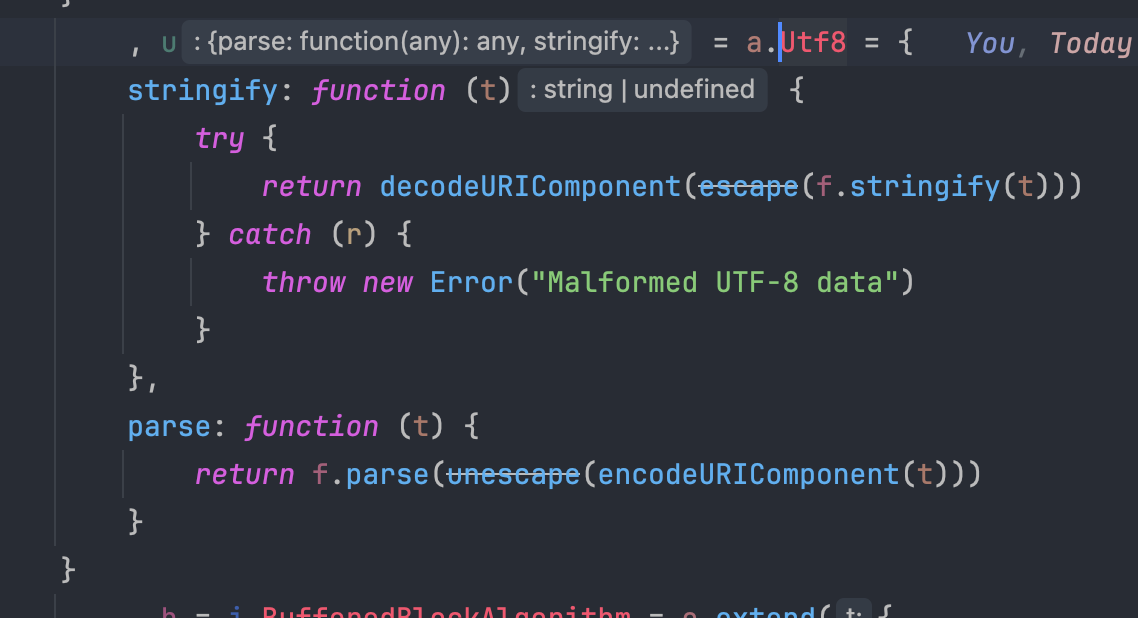
可以看到,其实 f 函数就是 a 变量,提前将各种函数包装了起来,用的时候通过 f 函数来调用。
根据以上结果可以分析出 token 算法,两个字符串,”/api/movie” 和时间戳放到一个数组中,使用逗号拼接到一起,计算 sha1 值后转成十六进制字符串,然后 sha1 值再和时间戳拼接到一起转成 base64 编码即可,和之前的算法是一样的。
最终代码见:https://github.com/libra146/learnscrapy/tree/main/js/antispider9
总结
本次实战基本上和上次的 OB 混淆差不多,只是增加了 webpack 和格式化检测等方式,花点时间还是可以做出来的。
本文章首发于个人博客 LLLibra146’s blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):
版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
