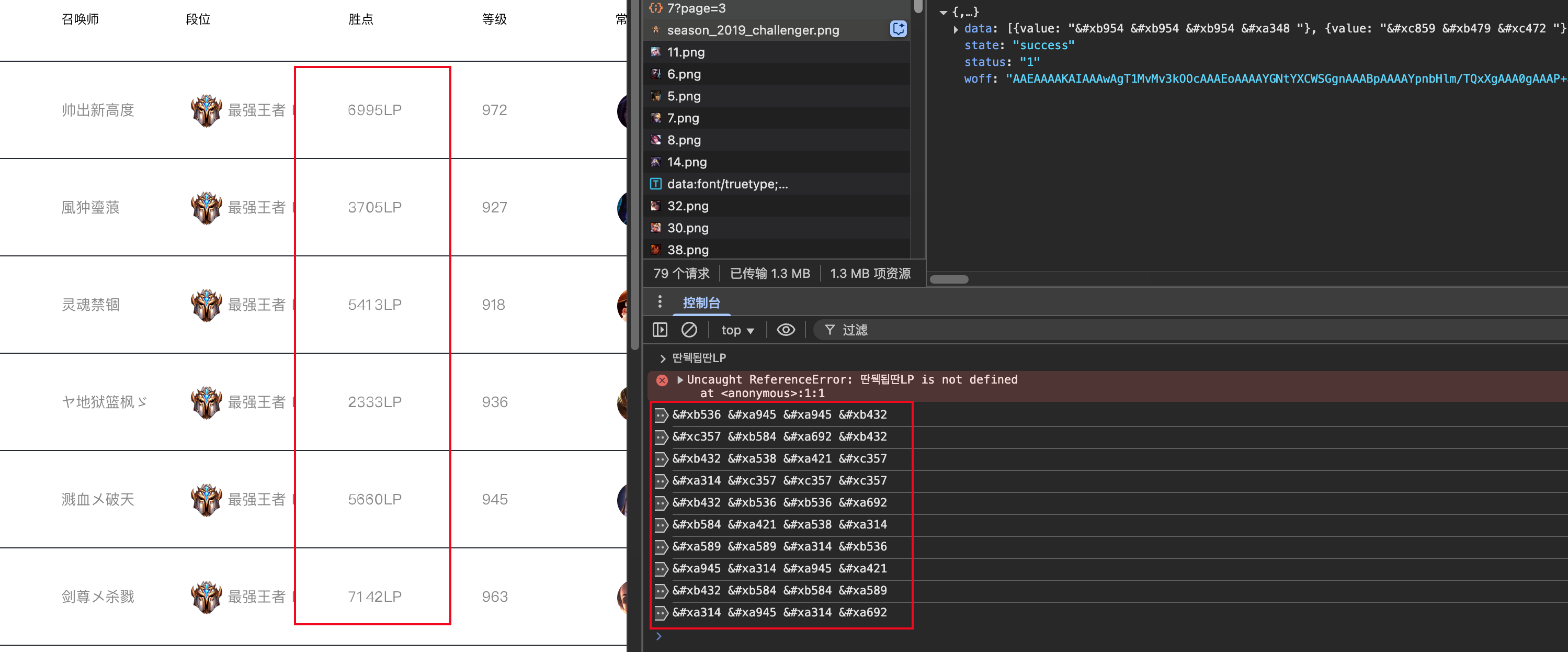
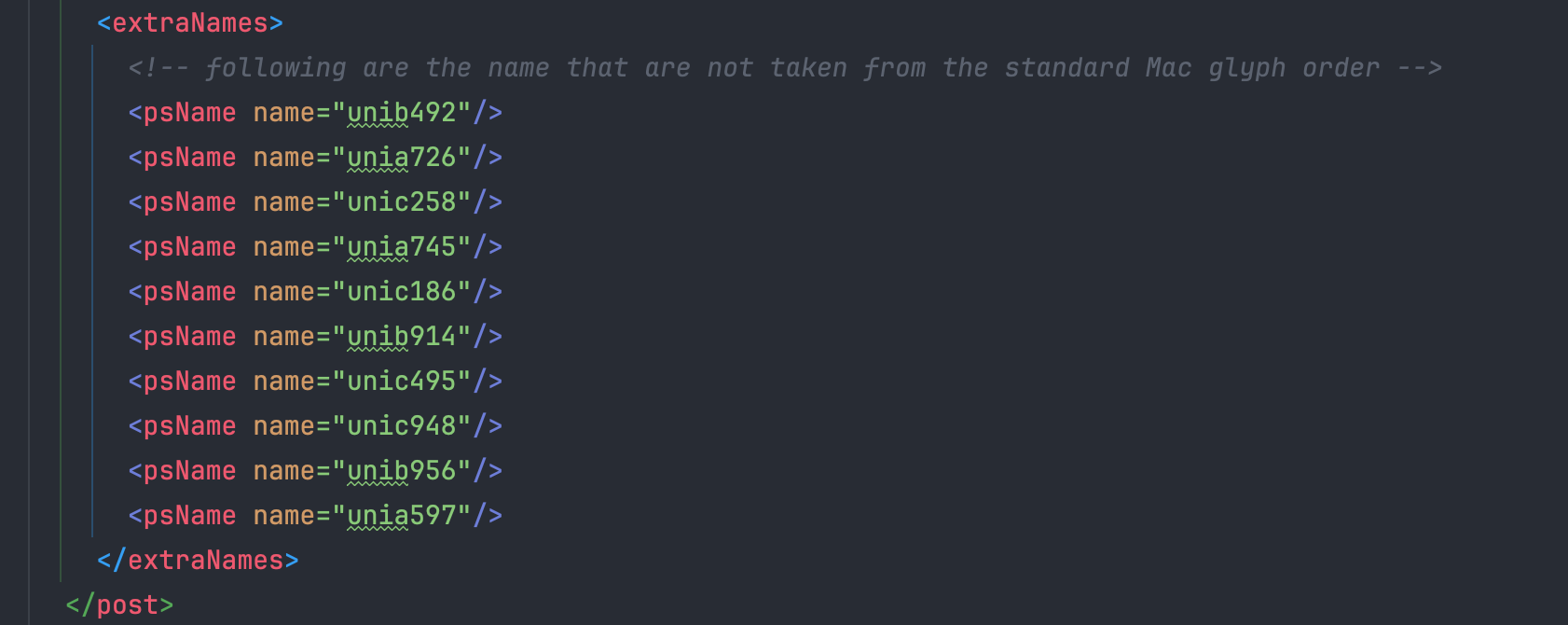
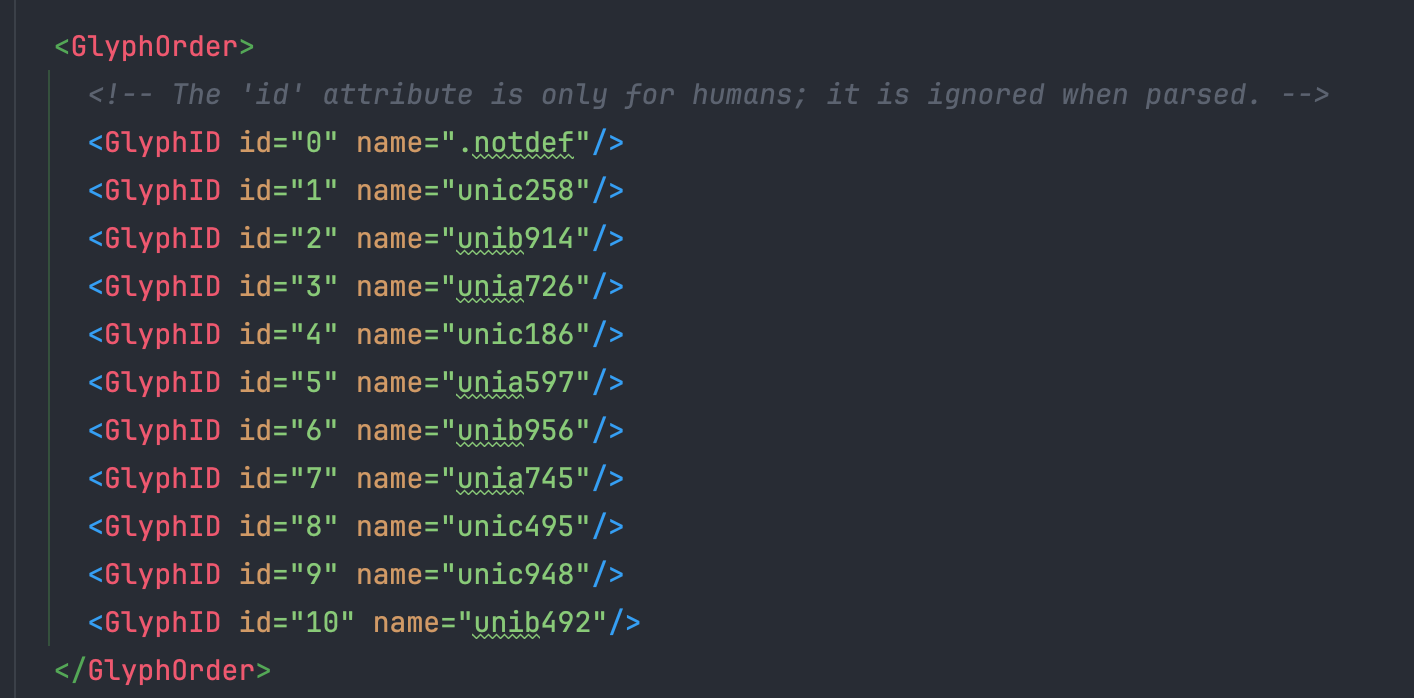
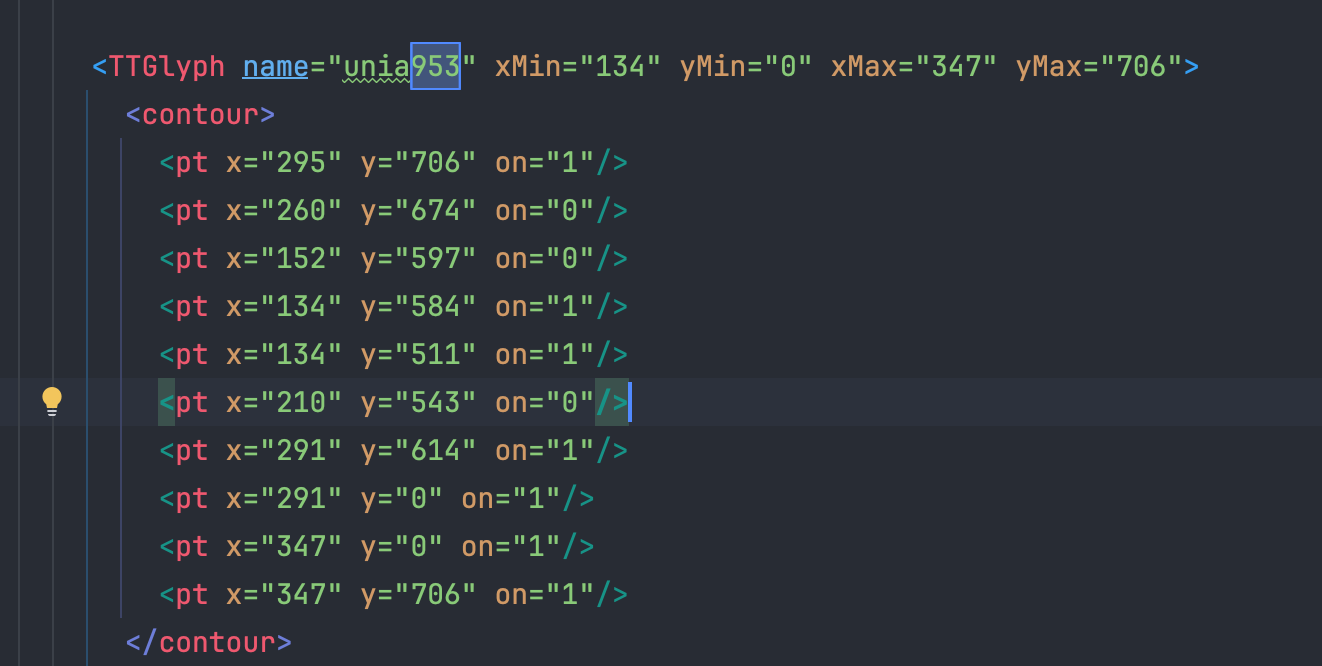
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| import base64
import requests
import urllib3
from fontTools.ttLib import TTFont
from lxml import etree
urllib3.disable_warnings()
result = 0
result_name = ''
headers = {
'content-length': '0',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'sec-ch-ua-platform': '"macOS"',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36',
'sec-ch-ua': '"Not(A:Brand";v="99", "Google Chrome";v="133", "Chromium";v="133"',
'dnt': '1',
'sec-ch-ua-mobile': '?0',
'accept': '*/*',
'origin': 'https://match.xxxxxx.cn',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://match.xxxxxx.cn/match/3',
'accept-encoding': 'gzip, deflate, br, zstd',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'sessionid=',
'priority': 'u=0, i',
}
number_dict = {
'1001101111': '1',
'1110101001001010110101010100101011111': '5',
'100110101001010101011110101000': '2',
'101010101101010001010101101010101010010010010101001000010': '8',
'111111111111111': '4',
'1111111': '7',
'10101010100001010111010101101010010101000': '6',
'10010101001110101011010101010101000100100': '9',
'10101100101000111100010101011010100101010100': '3',
'10100100100101010010010010': '0',
}
nodes_dict = {}
name = ['极镀ギ紬荕', '爷灬霸气傀儡', '梦战苍穹', '傲世哥', 'мaη肆風聲', '一刀メ隔世', '横刀メ绝杀', 'Q不死你R死你',
'魔帝殤邪', '封刀不再战', '倾城孤狼', '戎马江湖', '狂得像风', '影之哀伤', '謸氕づ独尊', '傲视狂杀', '追风之梦',
'枭雄在世', '傲视之巅', '黑夜刺客', '占你心为王', '爷来取你狗命', '御风踏血', '凫矢暮城', '孤影メ残刀',
'野区霸王', '噬血啸月', '风逝无迹', '帅的睡不着', '血色杀戮者', '冷视天下', '帅出新高度', '風狆瑬蒗',
'灵魂禁锢', 'ヤ地狱篮枫ゞ', '溅血メ破天', '剑尊メ杀戮', '塞外う飛龍', '哥‘K纯帅', '逆風祈雨', '恣意踏江山',
'望断、天涯路', '地獄惡灵', '疯狂メ孽杀', '寂月灭影', '骚年霸称帝王', '狂杀メ无赦', '死灵的哀伤', '撩妹界扛把子',
'霸刀☆藐视天下', '潇洒又能打', '狂卩龙灬巅丷峰', '羁旅天涯.', '南宫沐风', '风恋绝尘', '剑下孤魂', '一蓑烟雨',
'领域★倾战', '威龙丶断魂神狙', '辉煌战绩', '屎来运赚', '伱、Bu够档次', '九音引魂箫', '骨子里的傲气',
'霸海断长空', '没枪也很狂', '死魂★之灵']
def parse_glyph_ids(xml_string):
root = etree.fromstring(xml_string)
ttg = root.xpath("//TTGlyph")
for glyph in ttg:
name = glyph.get('name')
pt_nodes = glyph.xpath('.//contour/pt')
on_sequence = ''.join(pt.get('on') for pt in pt_nodes)
nodes_dict[name[-4:]] = number_dict.get(on_sequence)
for page in range(2, 6):
print(page)
url = f"https://match.xxxx.cn/api/match/7?page={page}"
response = requests.get(url, headers=headers, verify=False)
with open('font.ttf', 'wb') as f:
f.write(base64.b64decode(response.json()['woff']))
font = TTFont(file='font.ttf')
font.saveXML('font.xml')
with open('font.xml', 'rb') as f:
parse_glyph_ids(f.read())
for index, a in enumerate(response.json()['data'],1):
value = a['value']
num = ''.join([nodes_dict[b[-4:]] for b in value.split(' ') if b])
print(value,num)
if int(num) > result:
result = int(num)
result_name = name[index + (page - 1) * 10]
print(result_name)
print(result)
print(result_name)
|